全栈工程师和大数据工程师,该如何选择?


本文会围绕全栈和大数据讲解三个问题:两个方向的就业情况、如何选择方向以及面试准备。
全栈与大数据的就业情况
关于就业情况,我们先第一个大维度:从市场需求来说。

维度一:搜索热度
这是在Google Trend上找到的资源,红色是Big Data,蓝色是Full Stack。所以,从整个搜索热度上来看,两者基本不相上下。我们先关注一下红色的线条:17年下半年基本都是在50左右浮动,一直有一定的热度。根据美国劳工部门最新的统计,从2016到2026年,CS方向职位的增长是在13%左右,相比其他所有职位的增长率都要高。同时,在这些职位增长中,Cloud Computing,Big Data以及Information Security等占有比较大的比重。
接着来看全栈,蓝色线条也是有一个Ups and Downs。最近,蓝色有一条虚线,有一个缓缓上升的趋势。其实全栈本身相对比较全能,对于一些资源有限制的公司会非常受欢迎。从产品开发的角度来看,有些情况下工程师未必越多越好,有时候少数人更容易Iterate through,有更好的Product或者Project Development的效果。这是先从搜索热度的角度来看的。
维度二:职位数目
我们查询了北美职位开放的总数据,汇集成下表:
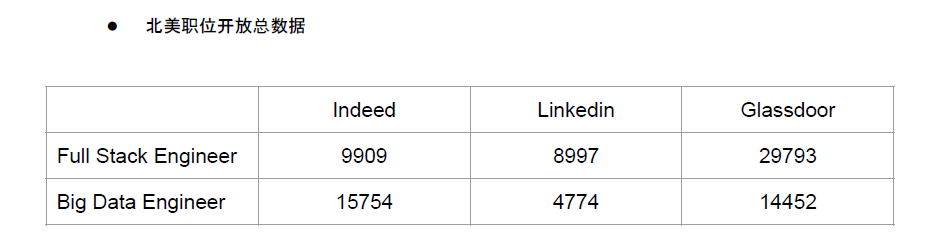
我们目前收集的是Full Stack Engineer和Big Data Engineer。仅从这两个职位上来看,数字已经比较可观了。
然后,我们再看一下国内的情况,观察了以下几个网站:
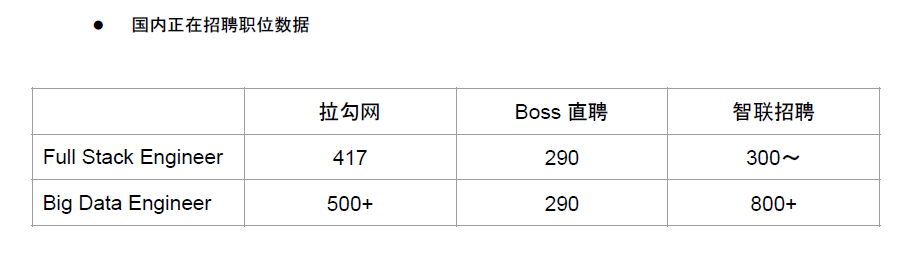
大家可以看到,数字上有一些变化,但是这个维度是正在招聘的职位数据,所以可以看出这两个方向相对而言数字还是比较庞大。
第三个维度:技术需求

上边的图是Stackoverflow统计的自2015年起200家企业使用的技术迭代的情况。根据Stack Overflow在17年底的数据统计,目前增长快速的技术包括了React, Docker, Apache Spark这些,跟全栈和大数据都是有关联的。
下图呈现的是一个供需对比:

条形柱越长,表示求越大于供。所以根据统计,现在需求较多的领域有Cloud Back End领域, iOS, Android开发。
第二个大的维度就是薪资水平

这是indeed.com上的一个调查,呈现的是北美的薪资水平。这两个方向的平均薪资其实没有太大区别。
第三个大维度:对应职位
对于Full Stack来说,我们罗列出了一些类似的职位。大家在找工作的时候可以参考,因为其实大家投递的时候一定不要太局限自己,Job Title要去广搜。根据自己具备的技术栈框架去搜索一些Job Opening。比如说Full Stack这边列了很相关的Web Development,Mobile还有Application Engineer;Big Data这边有Data Engineer, Back end, Platform, Infrastructure还有System Engineer。当然在搜索过程中,大家要相对应地去看一下JD,但是这可以打开大家去找Opening的广度。

如何选择合适的方向?
怎样扩展成全栈/Big Data?

其实这是非常灵活的,大家都会触类旁通,所以更重要的是按照自己的兴趣去发展。这两个方向都很难,都有很多工具、架构要练,所以兴趣是很关键的。如果你更喜欢研究用户行为,你会想怎样去Present一个数据更Make sense,怎样收集用户行为,跟用户做更多Interaction,那你更适合往全栈发展。如果你热爱数据,特别对系统的Performance有兴趣,认为自己可以Handle大量数据时特别Smooth,那肯定是往Big Data发展。
再往将来说,你越来越了解产品时甚至可以做PM,产品总监。实际上,我们BitTiger的创始人冯沁原老师是CS的PHD,在酷我做了大量的推荐系统,但是后来他就慢慢地做产品,成为了酷我的产品总监。走这条路绝对是很好的。
BigData这块,Handle Service是很多企业需要的。另外,Machine Learning这块也可以走一走,因为这个毕竟是Machine Learning的上游。所以做完上游,再做下游,可以往Machine Learning,AI靠一靠。当然,你得数学比较好,也比较感兴趣。
往前看,根据已有的技术基础判断自己有一个怎样的Foundation。但千万不要说很喜欢Big Data,但是将就做网站开发。关键还是一个学习动力。有人问哪个算法更难和简单,其实没有什么区别。这都是很Challenging的工作,这也是为什么能挣这么多啦。
面试考察
面试确实是因人而异。比如,你想进Google,不管是做全栈还是大数据你都要刷很多题。对System Design的考察也越来越多。但是小公司更多是考Project的经验。
整体面试考察
- Solid understanding of OO Design, Data Structure and Algorithm. 有都会被考到的东西:OO Design,Data Structure and Algorithm,这是大家必须会的。
- Fluent with Software Development Life Cycle. 整个一个Development的Cycle里,Test,Deployment,Release这块都要了解。全栈和Big Data都有自己的一套,这个必须要了解。
- Projects and every single detail of the projects. 当然,当被问到项目的时候,不管是Big Data还是全栈都会被问到大量的细节。比如Design Thinking、Trade-off,还有解决问题的经历。
- 最后,你要在面试中展示出信心。第一,对项目了如指掌的信心,第二,是表现自己是Fast Learner的信心。就算你以前的项目再契合,也不可能和你以后做的工作一样。所以你要展现出:“别管我以前做的什么,你现在交给我什么工作我都能相对独立地快速解决。”
全栈面试题目
- 当你在浏览器地址栏输入google.com并敲击enter后,发生了什么?
要求你非常了解Web Application的结构甚至涉及到DNSC和Load Balance。这一套结构要非常了解。
- 什么是进程、线程与协程?
现在Web Application大量应用单线程的架构,你现在就要了解单线程架构和传统多线程架构的区别和应用场景。
- 什么是容器,有什么作用?
容器在全栈和Big Data里都存在,处理的Serve Purpose都不一样。比如能让你开发更便捷,让开发环境统一,能快速Launch多个Service,让Service之间用SOA通信,而不是传统的Function Call的方式。
- Can you speed up this with multithreading?
- When do we use client-side load balance?
- Design a load balancer without using a centralized load dispatcher.
总的来说,你要能Handle一些Challenge,比如大量用户请求该怎么办?你用Load Balancer,后面怎么跟Server,Server哪些东西你可以Replicate等等各种问题。
大数据面试题目
- 给你一份乱序的100万个数字的文件,你如何来排序?
- What happens when the Kafka node goes down?
- 集群规模变大,文件数增多, NameNode内存受限成为瓶颈,如何解决?
- What are the logics to choose between Mesos and Yarn?
- How does spark treaming work with Kafka?
- How does Kafka manage its offset?
大数据主要还是在数据量上,基本大数据反而是比较简单的问题。这就是为什么Hadoop经常喜欢用WordCount,或者是给一堆数字排序。看上去非常简单,单机的话大家都会,因为都刷过题。只不过当这些数据量增大以后,伴随而来的是非常多单机的时候不会见到的Challenge。这些怎么解决?
当数据上来以后,你的任务节点可能就会死,要怎么Handle,如果是Master成为瓶颈应该怎么解决、Resource Management有不同的特点,Manage不同的Resources该怎么办,这方面的问题都需要了解。
那么,如何为求职面试做好充足准备?
BitTiger推出0 to 1高频算法面试题课程,金牌教师冯沁原为你详细讲解十二个常见算法问题,不仅让你学会如何掌握这些问题的解题代码,还会让你学到解决算法问题所必需的四类解题模板,让你轻松应对各类新问题。
↓↓↓


最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。