估值1200亿美元的Uber,最初架构大揭秘!


今天我们解读的是Uber公司的Curis所分享的Uber架构从0到1,我们之后会逐渐讲从1到万,以及更进一步各种RingPop的架构。
首先谈到Uber的初心,他们想实现一键打车功能。左边是Uber最早期的界面,大家可以看到跟现在有很大的区别,按一下就可以打到车了。

Uber的最初架构
为了支持这样的服务,Uber最初的架构是怎么样的呢?会很复杂吗?其实不会。

前面是一个手机,中间是PHP来负责业务逻辑,最后是MySQL的数据。司机每隔4秒上传自己的经纬数据来更新自己的位置,而这些数据会存在MySQL里,当用户请求来的时候,PHP会调用MySQL的查询语句来寻找匹配的司机。这是一个非常简单的架构,能够快速的支撑Uber的需求
架构扩展
那这样的架构如何扩展呢?因为Uber非常火爆,用户蜂拥而至,很简单的方法就是将PHP变成多进程多线程,可以同时访问MySQL得到数据。

但是这样的架构有很多缺点:
缺点一:一个司机两个乘客因为每个PHP是独立访问MySQL的,而有些机制没有做好的话,很可能一个司机被两个PHP进程查询到了后台,同时返回给两个用户,所以会出现一个司机被派给两个用户的情况。
缺点二:两个司机一辆车
有时候两个司机公用一辆车,他们用两个APP,这时候只能派遣一次,就会出问题。
缺点三:一个账号两辆车
两个用户登录同一个账号,这时你会看到用户的位置在不断的漂移,你会非常困惑。出现这么多问题,我们应该如何改进呢?
谈到改进,我们再把刚才的服务具体化,会有派遣服务,派遣服务后面是MySQL的存储状态,整体是一个实时逻辑,用户可以通过iphone,Android,SMS连在上面。谈到改进,这是一个逐步的过程,不可能一口吃一个胖子。

我们首先可以把一些影响我们派遣服务的逻辑拿出来。比如商业逻辑,像用户绑定手机号,付款之列,可以通过Python的API进行调用,因此减轻了派遣服务的能力。
再进一步,我们可以在中间加上消息队列,因为有各种请求,不见得所有请求都通过派遣服务走,像商业逻辑可以直接走API。而且消息队列在这里面可以抵挡更大的连接,更多的请求,本身还有个消息队列的机制。
同时为了存储一些比如GPS日志,可以在MongoDB里保存,从而也减轻了派遣服务。我们可以看到逐渐减轻派遣服务的压力。这之后大家如果在各个层级里出问题可以重试。重试很好,因为便于出错以后的恢复。但也存在一个隐患,稍后会讲到。
在这个基础上,我们还可以进一步变化,将派遣服务也变成Node.js,派遣数据变成MongoDB,这是非常好的。因为Javascript越来越全面,不仅可以写前端,而且还能写后端,所以跟Node.js搭配非常好。
MongoDB也用在这里,这时候另外一个优化是可以将很多数据放在内存里,所以派遣服务能够很快的去检索司机的匹配,而不需要通过MySQL的查询来实现。

如何避免单点失败?
什么是单点失败呢?比如我们的派遣服务是只有一个点的,叫Master,如果它挂了就坏了,所以最好的方法就是有几个Slave在热备,如果Master挂了就可以替换它,这叫做单点失败。同时如果大家请求特别多的话,也会有很大的压力,我们可以把不同的区分成三个区,每个区里负责单做自己区的服务,因此就避免了很多问题,而且每个区里都是进行单线程处理,意味着不会出现一个司机同时派给两个人的情况,这也是规避我们之前说的各种问题的诀窍,因此单线程服务是非常好的。
消息如何处理?
为了处理消息,我们需要一个消息管理器。这个管理器的代码很简单,首先监听端口9000,然后每获得一个请求就处理这个消息。这里有个思考题,我们如何能够热升级呢?我们想升级request manager,怎么做呢?这里就有问题存在,如果升级直接把它关掉,那以前处理到一半的消息怎么办?如果不关掉会一直接受请求永远无法关掉,有什么办法不损失消息还能把它重启呢?
答案是不要关掉服务,而是关掉它监听的端口。把端口关掉以后新来的请求进不来,它可以自己再持续服务1分钟,把之前的全部处理掉,然后再重启。在重启自己之后,刚才发过来的所有请求都会在外面进行重试,因为每一层有重试机制。所以这种规避错误的方法能够让请求得到满足,不出现任何问题,但它也是后面一个陷阱的起点。

服务器如何热备?
也是很简单的,我们需要一个SlaveMaster的结构。我们首先有一个server list,就是有很多很多的服务,这些服务启动起来,当每一个Master挂掉以后,大家发现了立马会有一个Slave新的Master来接替。同时你可以修理这个Master,保证这个服务不断地有三台在热备着,这就是一个选举机制。
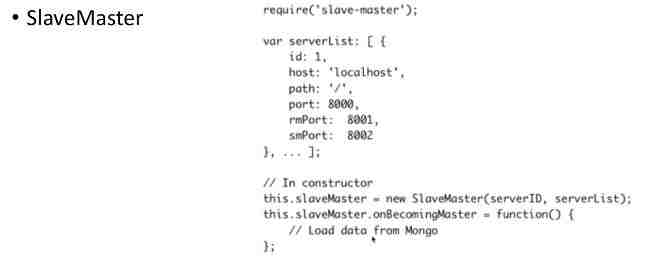
MongoDB是如何访问呢?
答案很简单,只要外面包一个Wrapper就好了,把访问的重试次数,如何备份,如何恢复数据,内容,配置等写到里面,这样大家统一调用就非常简单。那我们看下2011年数据:
- 平均请求 25/s
- 高峰请求 125/s
一般高峰期是平均的5倍左右。如果现在要了解这个架构能不能面对未来,怎么测试呢?用高峰的125/s测试吗?肯定不是的。需要一个更大值,比如1000。
为什么选择1000呢?它大概是高峰的10倍左右。如果你的系统是面向未来编程,一定要考虑至少三个月以后的数据变化情况。Uber是快速发展的服务,所以我们估算1000,是高峰乘以10倍。另外在这个基础上测试发现只占14%的CPU和60M内存,所以是完全可以顶得住这样的服务压力。
如何监控
长期来看,你不能保证系统永远正确,还需要有监控,那怎么监控呢?
- 出错以后可以立刻重启
- 邮件通知大家
- 有统计面板看
所以核心是在错误发生时先解决错误,继续服务是最重要的。所以先重启,之后再校正错误,如果没有这个机制,一发生错误就挂起来然后等待,就会出问题,手动重启更不行了。
最后思考一个问题
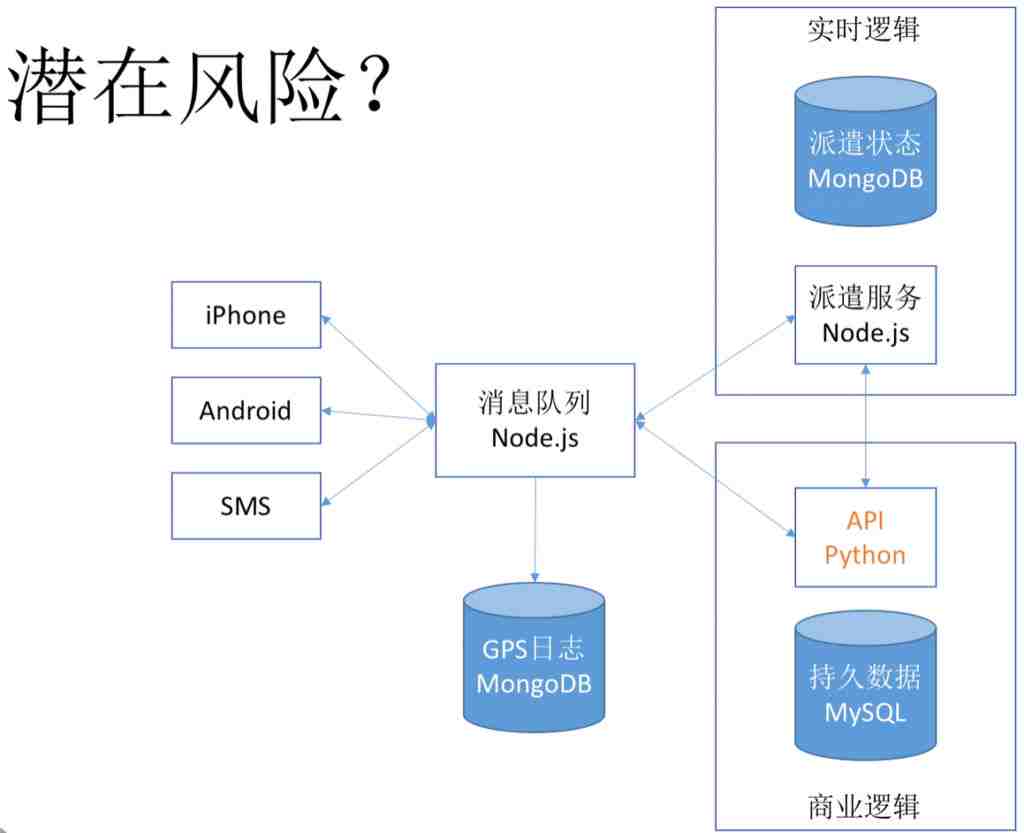
在这个架构里会有什么潜在风险呢?其中我们画出了API Python,我们之前也反复提到了各种隐患。这个时候会出现所谓的雪崩现象。比如这个API往往是商业逻辑,用户结算完后会算账去银行拿钱,但这个跟银行之间的对接往往比较慢,因为大家知道银行又慢又贵。由于很慢,别人在等的时候会不断的重试,重试以后会加大它的负担,所以就会挂掉,它挂掉以后别人再重试又不行。而且消息队列就会累积到一块去,于是他们也跟着挂掉。底层挂掉,上面跟着挂掉,所有的服务都挂掉,启动以后也没用,还是会挂掉,这就是雪崩现象。
一个挂了,其他跟着挂掉。那怎么破解呢?答案有两个:从根源上来说肯定是异步调用的问题,因为同步等待才造成问题的。另外总是不断的重试也是压死它的最后一根稻草,所以大家应该学会快速失败的机制。
总结
- JavaScript是个好兄弟任何一个能被JavaScript写的代码,最终都能被JavaScript所代替。
- 面向未来的程序设计要想3个月后会有多少压力,实在想不到先把用户量乘以10再说。
- 雪崩雪崩雪崩重要的事情说三遍
下篇精彩预告
Uber最早是做一键打车,她的使命是不断地进化把交通变为生活中像水和电一样的基本服务。那在这种使命上,它如何把系统升级呢?下一篇我们为大家分享一下Uber内部原理RingPop。
参考文献:Distributed Web Architectures: Curtis Chambers, Uber
让你拥中级Java和Spring开发能力,并且对企业中使用的主流技术有全面了解并具备动手能力。↓↓↓

很多同学反映扫码后网页加载困难,应该是网络的问题喔,你也可以点击“阅读原文”找到课程,或复制以下链接:
https://www.bittiger.io/livecourses

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。