教你轻松用SNAKE原则设计Netflix!


今天我们来聊一聊系统设计的基本方法——SNAKE原则(Scenario,Necessary,Application,Kilobit,Evolve),它是BitTiger创始人冯沁原在准备系统设计相关知识时整理出的一套方法论,非常适合用于系统设计的各个方面,无论宏观还是微观,初期还是晚期。

首先什么是系统设计?
The process of defining the architecture, components, modules, interfaces, and data for a system to satisfy specified requirements.
系统设计有四大要素。第一,是要满足一个需求即Requirements;第二,对内容进行一个定义;第三,从不同维度去考虑宏观的架构层、组件层、模块层;第四,也要考虑到互相间交流的接口和相关传递的数据。所以这些内容一起构成了整个系统设计。
系统设计有什么层次呢?从上向下是从概念层到逻辑层再到物理层,从清晰度来看,会从不清晰,到越来越清晰,到最清晰,角度则是从宏观到微观。换句话理解,如果系统设计时,我们从顶层向下做设计,那就是一个自上而下的方法;如果是自下层往顶层设计,就是一个自下而上的方法。在后文中我们分别称之为宏观设计与微观设计。我们以Netflix为例来讲这两个方法。

如何设计Netflix?
现在我们通过设计Netflix,来具体了解什么是系统设计的SNAKE原则。

这是Netflix的官方网页,上面有各种用户信息、搜索功能、以及列出的各个频道:Netflix流行的电影(Popular on Netflix)、当前的趋势(Trending Now)、惊险刺激电影(Exciting Movies)、漫画动画(Goofy Comedies)等等。每个电影类目下面会有很多具体的电影,如果点击可以看到详细内容,相信大家十分熟悉。
宏观设计
Scenario(场景):用例/接口
第一步:枚举在Netflix里面,到底有哪些场景
注册/登陆
播放电影
电影推荐
第二步:选出里面最重要的排序
基本需求:播放电影
获得频道
获得频道内电影
播放频道内电影
Necessary(限制):查看需求/假设
- 用户
- 首先看用户量,假设有5,000,000日活用户
- 第一步:询问
- 第二步:预测
- 通过日活用户,计算平均并发用户
- 日活用户/每日秒数*平均在线时长(假设为30min)
- 5,000,000 / (24 * 60 * 60) * (30 * 60)
- 104,167
- 高峰并发用户,通常是平均用户的2-10倍,这里假设为6倍
- 高峰并发用户 = 平均并发用户 * 6 = 625,000
- 假设未来3个月,Netflix用户涨2倍
- 3月后高峰并发用户 = 高峰并发用户 * 2 = 1,250,000
- 流量
- 单用户流量 = 3mbps(假设数据,满足看电影基本需求)
- 3月后高峰流量 = 1,250,000 * 3 mbps = 3.75 Tb/s
- 内存
- 单用户内存 = 10KB(假设用户数据不清空)
- 3月后高峰内存 = 5,000,000 * 2 * 10 KB= 100GB(当前日活用户500万,3个月后日活用户为2倍)
- 硬盘
- 电影数=14,000份,每部电影=50G(假设数据,且每部电影需要存储不同清晰度版本)
- 总硬盘=电影数*单电影空间=14,000*50GB=700TB
Application(应用):服务/算法
- 第一步:重放用例,添加请求
- 第二步:组合服务
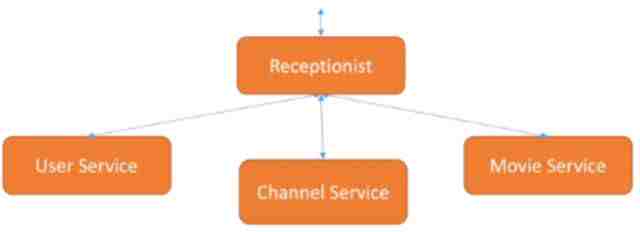
具体来看,我们有用户服务、频道服务和电影服务三种需求,在上面有一个接待员可以获得各种服务请求,接待员把所有服务接受完以后发送给后台的服务,就可以满足需求。
Kilobit(数据)
- 第一步:为每个请求添加服务模块
- 第二步:选择存储方式。对于用户数据用MySQL;频道数据用MongoDB;电影服务由于只是从文件出来,所以往往采取Movies的方式。

Evolve(进化)
- 第一步:分析
- 性能:单个点的计算能力如何,或某个算法的性能如何
- 扩展:如果机器或者用户量翻倍怎么办
- 鲁棒:发生各种危险,崩溃时服务器能不能处理
- 更好:限制性条件,10个用户变为100个
- 更广:场景,是否还有支付场景等
- 更深:细节,是否用CDN,如何部署
- 三个方向
- 三个角度
- 第二步:根据场景回溯并进化
以上是我们SNAKE五步原则在宏观设计中的应用。
微观设计
因为Netflix里推荐电影是最基本的一个需求,那我们就做一个具体的微观设计模块——推荐模块
如何设计推荐模块?

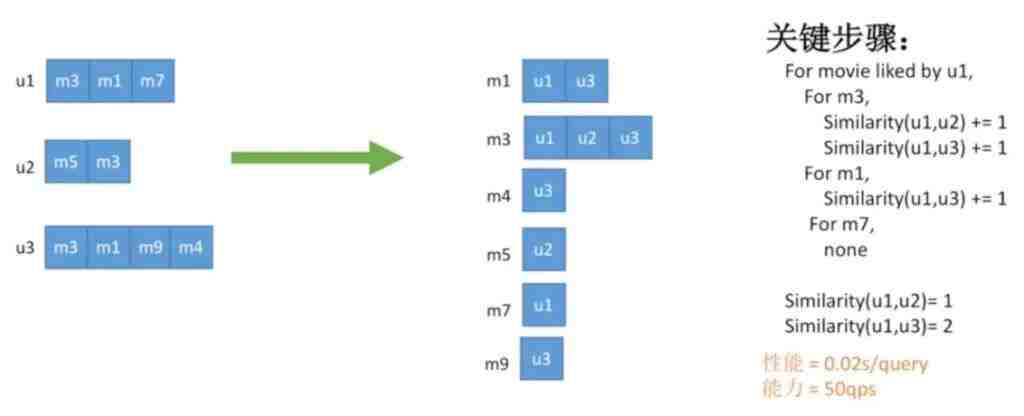
我们可以看到用户1和用户2重复喜欢的电影数有3个:m3、m5、m7。
我们的需求是:寻找一个用户的最相似用户。
Scenario(场景)
我们可以定义一个接口,定义之后直接找到我最相似的用户,输入一个用户ID,输出一个用户ID,接口就出来了。

Necessary(限制)
在微观设计里我们可以继续做预测,比如针对这个请求,它的QPS即每秒请求量是多少?

Algorithm(算法)&Kilobit(数据)
算法和数据在微观设计里往往可以放到一起。具体做时,不同的算法和不同的数据结构性能差异很大。
比如有3个用户u1,u2,u3,最简单的方法是两两比较。想算出与u1最相似的用户,就先把u1、u2比,发现相似度是1;u1、u3比,发现相似度是2。最终我们发现,这个算法的性能非常差,可能每一个计算都需要200毫秒,相当于每个计算节点只能计算5个QPS,而我们需要2000多QPS,明显无法达到。

Evolve(进化)
我们先看一下当前的架构:原始数据给推荐模块,推荐模块返回请求。
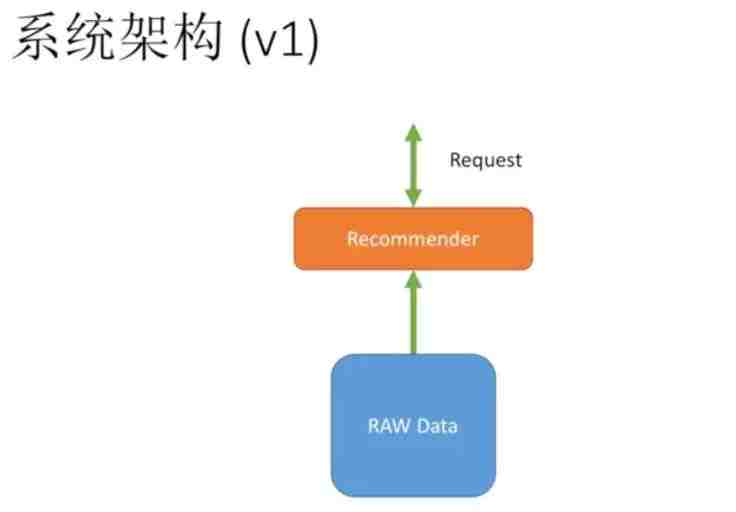
因此我们需要从性能、扩展、鲁棒三个维度来进化。
1. 提升性能
怎么提升性能?提升单点的计算能力?
我们通过建立倒排索引,能够非常简单地优化算法的性能。比如现在把由用户建立改为由电影建立,即先计算出每个电影被哪些用户喜欢。比如m3被用户1、2、3喜欢。我们先找u1喜欢的电影,这里是m1、m3、m7,然后轮流遍历这些电影,每当这个电影还被其他用户喜欢,则相似度+1。于是我们就可以降低n的复杂度,计算所有的相似度。这样复杂度就从n的三次方降为了n的平方。所以性能大大提升,变成了每个20毫秒,能实现单机50QPS,但仍然无法达到需要的2000+QPS。
这时的架构已经做了提升:通过加入一个准备器,将原始数据输入进来,并且创建索引返回给推荐器。

2. 提升扩展性
之前有了一个简单的架构,能计算出所有索引,现在需要将推荐模块全部平行地放进来。现在不仅有一个推荐模块,还可以有好几个推荐模块,同时上面还有一个分配器,把整个推荐模块的请求分配给不同推荐器来进行计算。

那么问题是:需要多少个推荐器来满足2083QPS呢?
其实很简单,因为刚才单个推荐模块能满足50QPS,所以用2083除以50就可以得出答案,当然也可以多算几个来进行缓冲。
3. 提高鲁棒性
提高鲁棒性,防止服务器崩溃,需要怎么办呢?答案是做热备。
之前的数据有1个人管理,推荐器有一个模块在运行,上面是管理者在管理。
现在可以热备出另外一个数据集,把它们放一起;同时也热备出一个推荐模块放在一起。下图中每个橙色的虚框表示一个集群组合在一起。顶层可以用Apache接外部服务器顶住请求。还会有一些记录日志,比如Big Brother。它们中间通过一个消息分配者把消息分配出去。
如果要给系统进行升级,我们可以通过添加模块来轻松地实现。比如想加入一个Feed流,相当于新浪微博这样的架构,那只需要把这个模块添加到系统中。
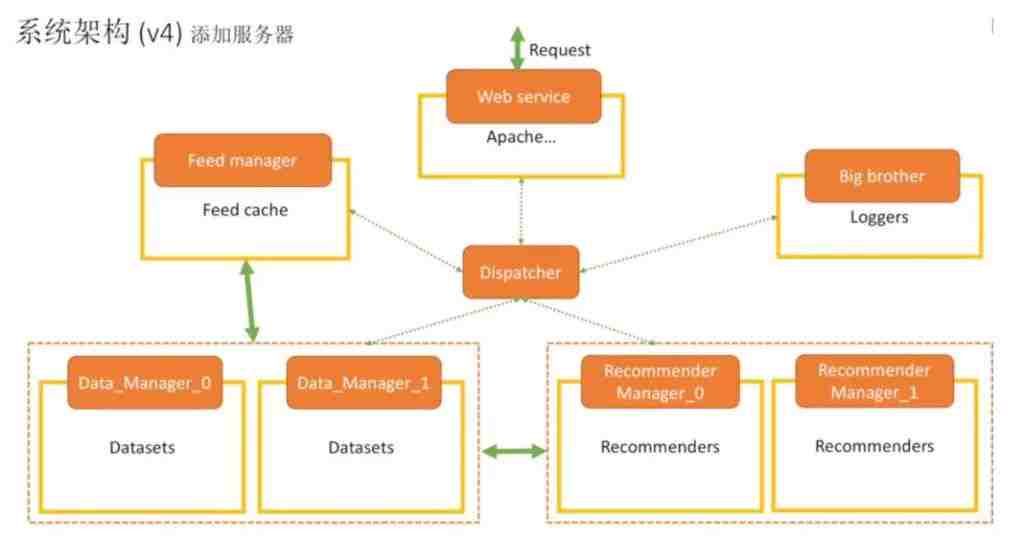
上图可以看到,绿色的虚线表示它们之间进行消息传递;而绿色粗线表示它们之间有一个数据的快速通道,这样就不用所有消息都通过中间的消息传递者传输,避免影响效率。
总结:SNAKE原则
- Scenario(场景)
- 枚举&排序
- Necessary(限制)
- 咨询&预测
- Application(应用)
- 重访&组合
- Kilobit(数据)
- 添加&选择
- Evolve(进化)
- 分析&回溯
通过项目的搭建,建立Solid的系统设计思维,真正了解系统设计中会遇到的问题,并亲手解决这些问题,提升50%你的学习效率。
李超老师带你从0到1,用Elasticsearch搭建自己的搜索服务,并学习和巩固Elasticsearch,Django,Scrapy 等方面知识。↓↓↓


最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。