NeurIPS23|视觉 「读脑术」:从大脑活动中重建你眼中的世界

机器之心专栏
机器之心编辑部
在这篇 NeurIPS23 论文中,来自鲁汶大学、新加坡国立大学和中科院自动化所的研究者提出了一种视觉 「读脑术」,能够从人类的大脑活动中以高分辨率出解析出人眼观看到的图像。
人类的感知不仅由客观刺激塑造,而且深受过往经验的影响,这些共同促成了大脑中的复杂活动。在认知神经科学领域,解码大脑活动中的视觉信息成为了一项关键任务。功能性磁共振成像(fMRI)作为一种高效的非侵入性技术,在恢复和分析视觉信息,如图像类别方面发挥着重要作用。
然而,由于 fMRI 信号的噪声特性和大脑视觉表征的复杂性,这一任务面临着不小的挑战。针对这一问题,本文提出了一个双阶段 fMRI 表征学习框架,旨在识别并去除大脑活动中的噪声,并专注于解析对视觉重建至关重要的神经激活模式,成功从大脑活动中重建出高分辨率且语义上准确的图像。
论文链接:https://arxiv.org/abs/2305.17214
项目链接:https://github.com/soinx0629/vis_dec_neurips/
论文中提出的方法基于双重对比学习、跨模态信息交叉及扩散模型,在相关 fMRI 数据集上取得了相对于以往最好模型接近 40% 的评测指标提升,在生成图像的质量、可读性及语义相关性相对于已有方法均有肉眼可感知的提升。该工作有助于理解人脑的视觉感知机制,有益于推动视觉的脑机接口技术的研究。相关代码均已开源。
功能性磁共振成像(fMRI)虽广泛用于解析神经反应,但从其数据中准确重建视觉图像仍具挑战,主要因为 fMRI 数据包含多种来源的噪声,这些噪声可能掩盖神经激活模式,增加解码难度。此外,视觉刺激引发的神经反应过程复杂多阶段,使得 fMRI 信号呈现非线性的复杂叠加,难以逆转并解码。
传统的神经解码方式,例如岭回归,尽管被用于将 fMRI 信号与相应刺激关联,却常常无法有效捕捉刺激和神经反应之间的非线性关系。近期,深度学习技术,如生成对抗网络(GAN)和潜在扩散模型(LDMs),已被采用以更准确地建模这种复杂关系。然而,将视觉相关的大脑活动从噪声中分离出来,并准确进行解码,依然是该领域的主要挑战之一。
为了应对这些挑战,该工作提出了一个双阶段 fMRI 表征学习框架,该方法能够有效识别并去除大脑活动中的噪声,并专注于解析对视觉重建至关重要的神经激活模式。该方法在生成高分辨率及语义准确的图像方面,其 50 分类的 Top-1 准确率超过现有最先进技术 39.34%。
方法概述
fMRI 表征学习 (FRL)
第一阶段:预训练双对比掩模自动编码器 (DC-MAE)
为了在不同人群中区分共有的大脑活动模式和个体噪声,本文引入了 DC-MAE 技术,利用未标记数据对 fMRI 表征进行预训练。DC-MAE 包含一个编码器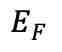 和一个解码器
和一个解码器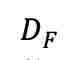 ,其中以遮蔽的 fMRI 信号为输入,
,其中以遮蔽的 fMRI 信号为输入,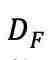 则被训练以预测未遮蔽的 fMRI 信号。所谓的 “双重对比” 是指模型在 fMRI 表征学习中优化对比损失并参与了两个不同的对比过程。
则被训练以预测未遮蔽的 fMRI 信号。所谓的 “双重对比” 是指模型在 fMRI 表征学习中优化对比损失并参与了两个不同的对比过程。
在第一阶段的对比学习中,每个包含 n 个 fMRI 样本 v 的批次中的样本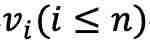 被随机遮蔽两次,生成两个不同的遮蔽版本
被随机遮蔽两次,生成两个不同的遮蔽版本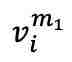 和
和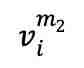 ,作为对比的正样本对。随后,1D 卷积层将这两个版本转换为嵌入式表示,分别输入至 fMRI 编码器。解码器 接收这些编码的潜在表示,产生预测值
,作为对比的正样本对。随后,1D 卷积层将这两个版本转换为嵌入式表示,分别输入至 fMRI 编码器。解码器 接收这些编码的潜在表示,产生预测值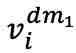 和
和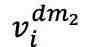 。通过 InfoNCE 损失函数计算的第一次对比损失,即交叉对比损失,来优化模型:
。通过 InfoNCE 损失函数计算的第一次对比损失,即交叉对比损失,来优化模型:
在第二阶段对比学习中,每个未遮蔽的原始图像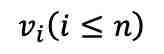 及其相应的遮蔽图像
及其相应的遮蔽图像 形成一对天然正样本。这里的
形成一对天然正样本。这里的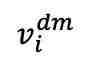 代表解码器预测出的图像。第二次对比损失,也就是自对比损失,根据以下公式进行计算:
代表解码器预测出的图像。第二次对比损失,也就是自对比损失,根据以下公式进行计算:
优化自对比损失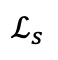 能够实现遮蔽重建。无论是
能够实现遮蔽重建。无论是 还是,负样本
还是,负样本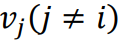 都来自同一批次的实例。和共同按如下方式优化:
都来自同一批次的实例。和共同按如下方式优化: ,其中超参数
,其中超参数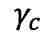 和
和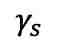 用于调节各损失项的权重。
用于调节各损失项的权重。
- 第二阶段:使用跨模态指导进行调整
考虑到 fMRI 记录的信噪比较低且高度卷积的特性,专注于与视觉处理最相关且对重建最有信息价值的大脑激活模式对 fMRI 特征学习器来说至关重要。
在第一阶段预训练后,fMRI 自编码器通过图像辅助进行调整,以实现 fMRI 的重建,第二阶段同样遵循此过程。具体而言,从 n 个样本批次中选择一个样本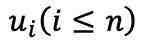 及其对应的 fMRI 记录的神经反应
及其对应的 fMRI 记录的神经反应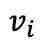 。
。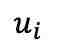 和经过分块和随机遮蔽处理,分别转变为
和经过分块和随机遮蔽处理,分别转变为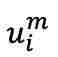 和,然后分别输入到图像编码器
和,然后分别输入到图像编码器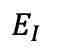 和 fMRI 编码器中,生成
和 fMRI 编码器中,生成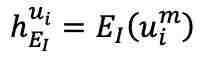 和
和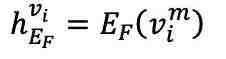 。为重建 fMRI,利用交叉注意力模块将
。为重建 fMRI,利用交叉注意力模块将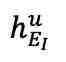 和
和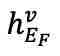 进行合并:
进行合并:
W 和 b 分别代表相应线性层的权重和偏置。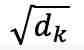 是缩放因子,
是缩放因子,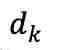 是键向量的维度。CA 是交叉注意力(cross-attention)的缩写。
是键向量的维度。CA 是交叉注意力(cross-attention)的缩写。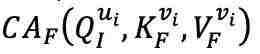 加上
加上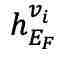 后,输入到 fMRI 解码器中以重建,得到
后,输入到 fMRI 解码器中以重建,得到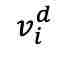 :
:
图像自编码器中也进行了类似的计算,图像编码器的输出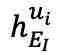 通过交叉注意力模块
通过交叉注意力模块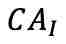 与的输出合并,然后用于解码图像,得到
与的输出合并,然后用于解码图像,得到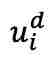 :
:
通过优化以下损失函数,fMRI 和图像自编码器共同进行训练:
使用潜在扩散模型 (LDM) 生成图像
在完成 FRL 第一阶段和第二阶段的训练后,使用 fMRI 特征学习器的编码器来驱动一个潜在扩散模型(LDM),从大脑活动生成图像。如图所示,扩散模型包括一个向前的扩散过程和一个逆向去噪过程。向前过程逐渐将图像降解为正态高斯噪声,通过逐渐引入变方差的高斯噪声。
该研究通过从预训练的标签至图像潜在扩散模型(LDM)中提取视觉知识,并利用 fMRI 数据作为条件生成图像。这里采用交叉注意力机制,将 fMRI 信息融入 LDM,遵循稳定扩散研究的建议。为了强化条件信息的作用,这里采用了交叉注意力和时间步条件化的方法。在训练阶段,使用 VQGAN 编码器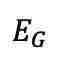 和经 FRL 第一和第二阶段训练的 fMRI 编码器 处理图像 u 和 fMRI v,并在保持 LDM 不变的情况下微调 fMRI 编码器,损失函数为:
和经 FRL 第一和第二阶段训练的 fMRI 编码器 处理图像 u 和 fMRI v,并在保持 LDM 不变的情况下微调 fMRI 编码器,损失函数为:
其中,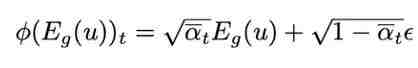 是扩散模型的噪声计划。在推理阶段,过程从时间步长 T 的标准高斯噪声开始,LDM 依次遵循逆向过程逐步去除隐藏表征的噪声,条件化在给定的 fMRI 信息上。当到达时间步长零时,使用 VQGAN 解码器
是扩散模型的噪声计划。在推理阶段,过程从时间步长 T 的标准高斯噪声开始,LDM 依次遵循逆向过程逐步去除隐藏表征的噪声,条件化在给定的 fMRI 信息上。当到达时间步长零时,使用 VQGAN 解码器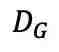 将隐藏表征转换为图像。
将隐藏表征转换为图像。
实验
重建结果
通过与 DC-LDM、IC-GAN 和 SS-AE 等先前研究的对比,并在 GOD 和 BOLD5000 数据集上的评估中显示,该研究提出的模型在准确率上显著超过这些模型,其中相对于 DC-LDM 和 IC-GAN 分别提高了 39.34% 和 66.7%
在 GOD 数据集的其他四名受试者上的评估显示,即使在允许 DC-LDM 在测试集上进行调整的情况下,该研究提出的模型在 50 种方式的 Top-1 分类准确率上也显著优于 DC-LDM,证明了提出的模型在不同受试者大脑活动重建方面的可靠性和优越性。
实验结果表明,利用所提出的 fMRI 表示学习框架和预先训练的 LDM,可以更好的重建大脑的视觉活动,大大优于目前的基线。该工作有助于进一步挖掘神经解码模型的潜力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]
阅读原文 关键词
图像
技术
大脑活动
信息
视觉
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。