NeurIPS 2021 | 微软亚洲研究院机器学习领域最新研究一览
平均阅读时长为 2分钟


(本文阅读时间:26分钟)
编者按:NeurIPS(Conference on Neural Information Processing Systems)是全球顶尖神经信息处理系统大会,也是机器学习和计算神经科学领域的顶级国际学术会议。今年的 NeurIPS 大会于12月6日至14日在线上举办。在本届大会中,微软亚洲研究院共有33篇论文入选,涵盖人工智能的多个领域。今天,我们精选了其中的7篇来为大家进行简要介绍。欢迎感兴趣的读者阅读论文原文,一起了解机器学习和计算神经科学领域的前沿进展!
01
“预测+优化”中含软约束问题的代理目标函数求解框架

论文链接:
https://arxiv.org/abs/2111.11358
数学优化广泛应用在生活中的决策问题中——如资源调度、生产规划、投资组合等。由于现实中优化问题的参数往往是未知的,因此通常需要“先预测再优化”,例如,求解最优股票投资组合需要预测股票价格,所以预测模型对决策质量至关重要。传统来说,预测模型通过最小化与真实值误差的损失函数学得。但是,当预测模型存在偏差时,预测误差与优化问题解的好坏经常不一致。为此,“预测+优化”的端到端方法,即用最终优化解的损失直接训练预测模型,成为当前的研究方向。
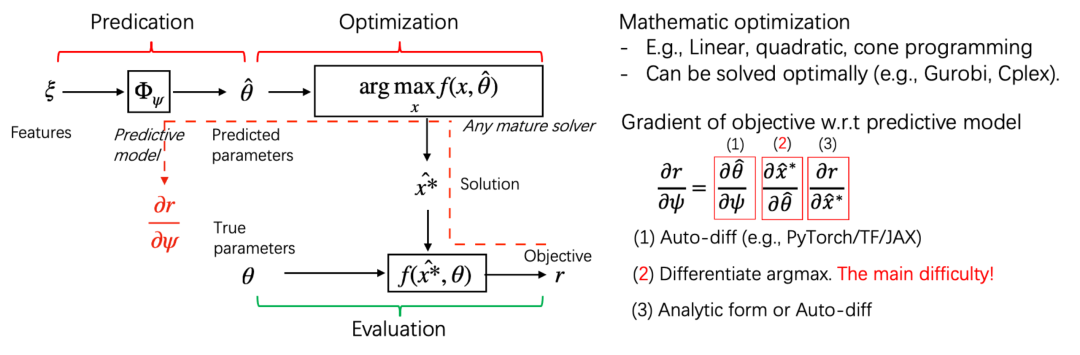
图1:预测+优化的端到端方法计算图
在该研究方向中,微软亚洲研究院的研究员们考虑优化的是目标函数中含软约束项(即max(z=f(x), 0))的问题。软约束可以表达非对称误差或损失、超过阈值损失等,在实际应用中非常重要。但是,由于 max 本身在 z=0 处不可微,且即使采用次梯度也无法满足二阶可微的要求,因此现有预测+优化方法(如CVXPY2.0)无法有效求解。
针对约束参数非负的一大类线性和二次规划实际问题,研究员们提出了一种代理函数方法框架。该框架的主要贡献在于:(1)理论上证明参数非负的线性约束可以转变成软约束,并给出了其乘数的界;(2)给出软约束的一种连续、二阶可微的分段代理函数;(3)针对目标函数扩展软约束项后的无(硬)约束线性和半正定二次规划,给出了其最优解关于参数的微分的解析表达式(即 (∂(x^* ) ̂)/(∂θ ̂ ))。另外,与之前的工作相比,此方法不需要对 KKT 条件求微分,从而极大地提高了计算效率。
针对三个实际中有代表性的问题——目标函数扩展软约束项的线性规划、投资组合(半正定二次规划)和资源供应(非对称损失),此方法在实验中取得了比传统的两阶段法(预测模型基于 L1或 L2 误差)和其他预测+优化方法稳定更好的性能。表1给出了第一个问题的实验结果对比。其他实验结果请详见论文。
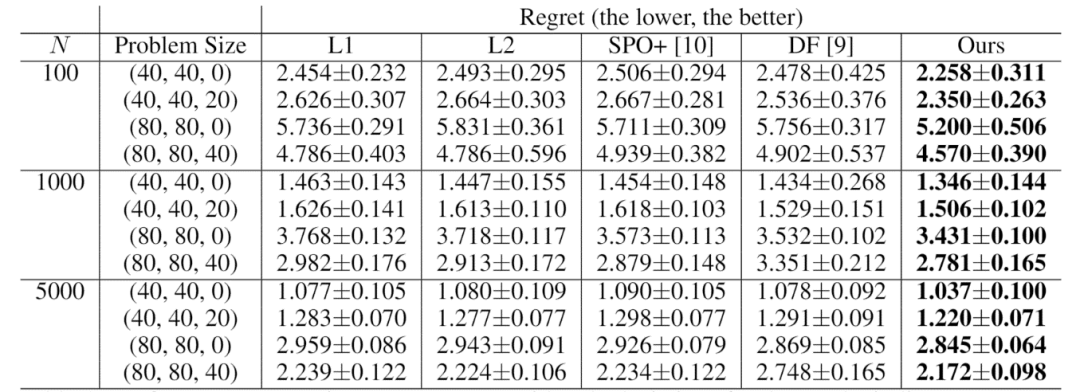
表1:不同预测模型学习方法求解带软约束的线性规划问题的性能对比
总之,本篇论文在“预测+优化”框架下,将一大类现实问题的特点作为合理假设,解决了软约束的微分问题,对于推动该领域方法的大规模实际应用具有重要意义。
02
GraphFormers:用于文本图表示学习的GNN嵌套Transformer模型

论文链接:
https://arxiv.org/abs/2105.02605
代码链接:
https://github.com/microsoft/GraphFormers
文本图上的表示学习(Textual Graph Representation)旨在构建融合中心与邻域文本特征的图节点向量表示,在文本检索、在线广告、推荐系统中有着广泛的应用。预训练语言模型(PLM: Pretrained Language Model)与图神经网络(GNN: Graph Neural Network)是生成高质量文本图表示的基本模块。目前,主流研究通常借助级联的架构(Cascaded Framework,如图2.A)来整合 PLM 与 GNN [1,2],即先由 PLM(e.g., BERT[4])生成各个节点的文本表示,再借助 GNN(e.g., GraphSage[3])来融合中心节点与邻域的语义。科研人员认为级联架构是一种相对低效的整合模式:在 PLM 的编码阶段,各个节点无法有效参照邻域节点的语义信息,进而对文本表示的质量产生不利的影响。
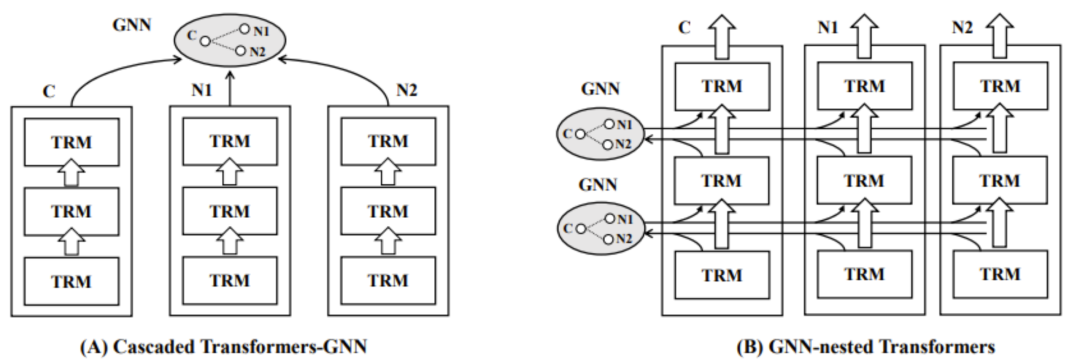
图2:模型架构对比
对此,微软亚洲研究院的研究员们提出了一种 GNN 与 PLM 深度融合的网络架构 GraphFormers(GNN-nested Transformers,如图2.B)。GraphFormers 采取了层级化的 PLM-GNN 整合方式(如图3):在每一层中,每个节点先由各自的 Transformer Block 进行独立的语义编码,编码结果汇总为该层的特征向量(默认由 CLS 所关联的 hidden state 来表征);然后各节点的特征向量汇集到该层的 GNN 模块进行信息整合;之后信息整合的结果会被编码至对应各个节点的图增广(graph augmented)特征向量中,并分发至各个节点;然后各节点会依照图增广特征向量再进行下一层级的编码。相较于此前的级联架构,GraphFormers 在 PLM 编码阶段充分参照了邻域信息,从而大大提升了各节点文本表示的质量。同时,考虑到节点间的信息交互是借由特征向量在极其轻量的 GNN 模块中进行的,每层整体的运算开销与单纯利用Transformer Block 进行各节点独立的编码相差无几。
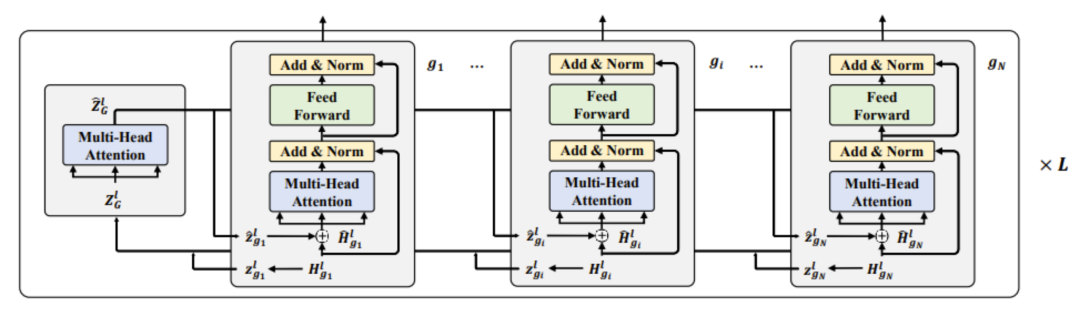
图3:GNN-nested Transformers 详细结构
本篇论文就“边预测任务“比较了 GraphFormers 与目前主流的基于级联架构的方法在三个大规模文本图数据集上的表现。实验结果显示,GraphFormers 在各个数据集上均取得了预测精度的大幅提升,进而证明了其强大的语义表征能力(如表2)。

表2:不同方法在3个数据集上的性能对比。GraphFormers 在3个数据集上的性能都超越了之前的 SOTA 模型。
本文同时也就推理效率进行了评估:相比传统的级联架构,GraphFormers 在引入了不同数量邻居时所带来的额外开销微乎其微,从而验证了其高效性与可扩展性(如表3)。目前,GraphFormers 已成功应用于微软 Bing Search Ads 的生产线,显著提升了广告点击量与营收(如图4)。该方法与模型现已开源,希望可以促进今后图文本表示的技术发展。

表3:模型的时空开销对比。相对原先的级联结构,GraphFormers 的额外开销微乎其微。
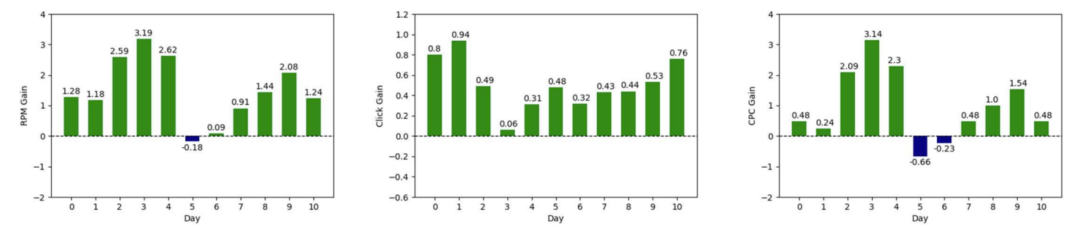
图4:线上 A/B 测试。从左至右分别是RPM,CY 和 CPC 的相对提升(绿色为增长,蓝色为下降)。
03
任务导向的无监督域自适应

论文链接:
https://arxiv.org/abs/2106.10812
代码链接:
https://github.com/microsoft/UDA
在过去几年,深度学习在各种任务上都取得了巨大的成功。然而,由于数据分布的差异,当把模型应用到与训练数据分布不一致的场景时,其效果往往不尽如人意。为了有效地解决这一问题,无监督的域自适应(UDA)技术逐渐发展并得到了广泛关注。
无监督的域自适应技术主要关注如何在新的场景中利用已有的有标签数据来做训练,使得在新的目标数据域中也会取得较好的性能。目前主流的 UDA 技术着眼于如何将源数据域和目标域的特征通过对齐来减小分布的差异。微软亚洲研究院的研究员们分析发现,这一类的方法往往会将两个域的特征分别看成整体来对齐,并没有考虑到特征对齐任务目的是为了更好的服务于主要的任务(比如分类)。如果没有正确的引导,这样对齐的特征并不能保证有效地帮助目标域上的分类任务。
因此,针对这一情况,研究员们提出了一种可以广泛应用的 UDA 方法-ToAlign,旨在对齐两个域的特征分布时能够在分类任务知识的引导下,朝着服务分类任务的方向进行优化。受到可解释性方法中常用的 GradCAMs 启发,研究员们利用分类任务中的梯度,显示地将分类任务的知识引入到了特征对齐任务,以实现任务导向下的特征对齐。ToAlign 的方法适用于目前绝大多数基于特征对齐来实现域自适应的方法。通过实验,研究员们验证了 ToAlign 能在无监督、半监督的域自适应任务中都取得最好的结果。可视化结果也验证了 ToAlign 确实可以让目标域上学到的特征更多关注于对分类有帮助的前景物体。
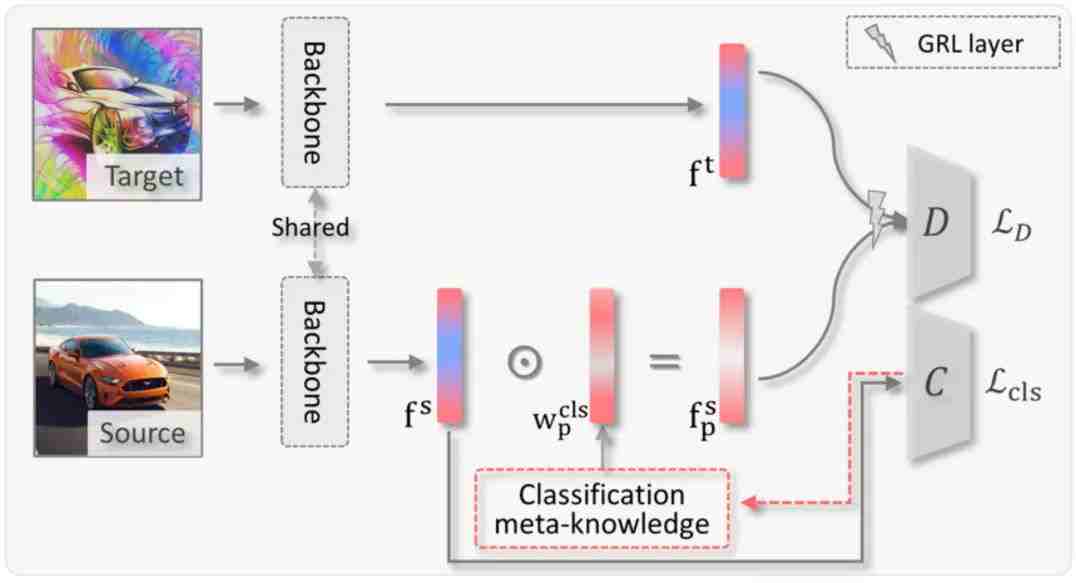
图5:ToAlign 网络结构。在特征对齐过程中,分类任务的知识被显式地引入,以此来实现任务导向下的特征对齐。

图6:可视化结果显示,相比于其他方法,ToAlign 更多的关注于前景的物体。
04
MixTraining: 一种全新的物体检测训练范式

论文链接:
https://arxiv.org/abs/2111.03056
代码链接(即将开源):
https://github.com/MendelXu/MixTraining
物体检测是计算机视觉中的基础课题。经典的物体检测器通常采用单一的数据增强策略,并简单地使用人工标注的物体包围盒来进行训练,这种训练策略也被称为 SiTraining 范式。在本篇论文中,微软亚洲研究院的研究员们提出了一种全新的物体检测训练范式:MixTraining。该范式通过引入 Mixed Training Targets(混合训练目标)与 Mixed Data Augmentation(混合数据增广),可以有效提升现有物体检测器性能,并且不会在测试阶段增加任何额外的开销。如表4所示,MixTraining 能够将基于 ResNet-50 的 Faster R-CNN 的检测精度从41.7mAP 提升至44.3 mAP,并将基于 Swin-S 的 Cascade R-CNN 的检测精度从 50.9mAP 提升至 52.8mAP。
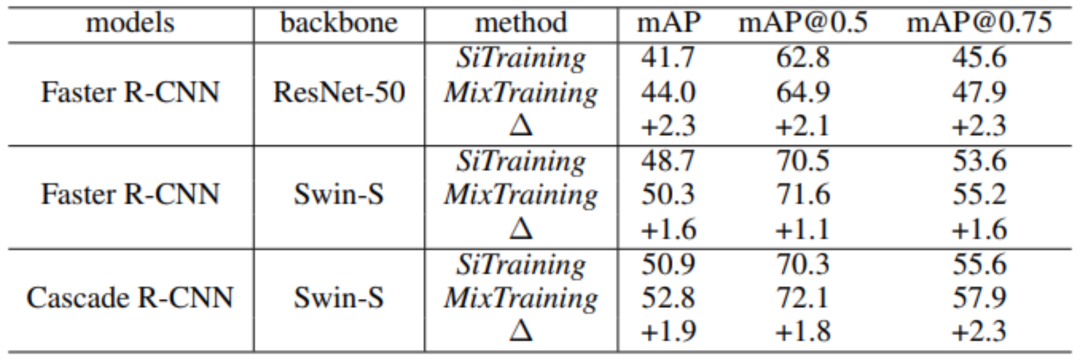
表4:MixTraining 可以有效提升多种现有检测器的检测性能
除了良好的系统级性能提升以外,研究员们还对该范式为何有效进行了深入详尽的分析与研究。研究员们首先对 Mixed Training Targets (混合训练目标)的工作机理进行了分析。Mixed Training Targets (混合训练目标)采用了老师-学生 (Teacher-Student)架构来生成高质量的检测结果,并将这些检测结果作为伪标注(Pseudo ground-truth)再与真实的人类标注 (Human-annotated ground-truth)结合起来共同作为网络的训练标注。研究员们发现这种使用混合标注有两种好处:1)可以避免漏标的物体(missing label) ;2)可以降低标注中的定位噪声(box loc noise) 。分析结果如表5所示。
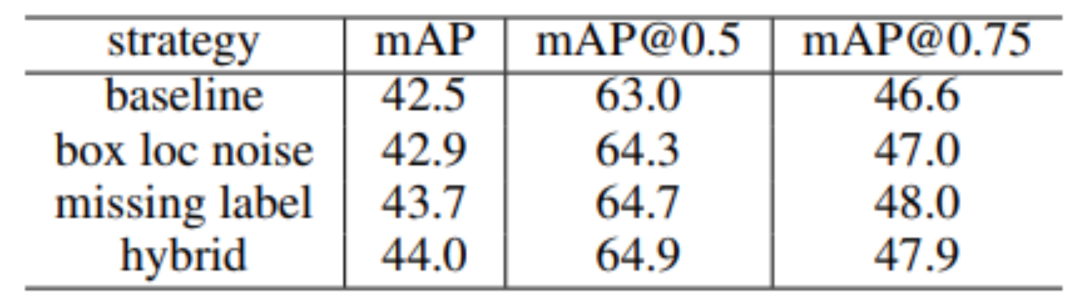
表5:对混合训练目标的消融实验
其次,研究员们还对 Mixed Data Augmentation(混合数据增广)进行了进一步的研究。研究员们猜测不同的训练实例可能需要不同强度的数据增广,而不能一概而论地对所有训练示例使用统一的简单或者过强的数据增广,否则反而有可能会损害训练性能,结果如表6所示。
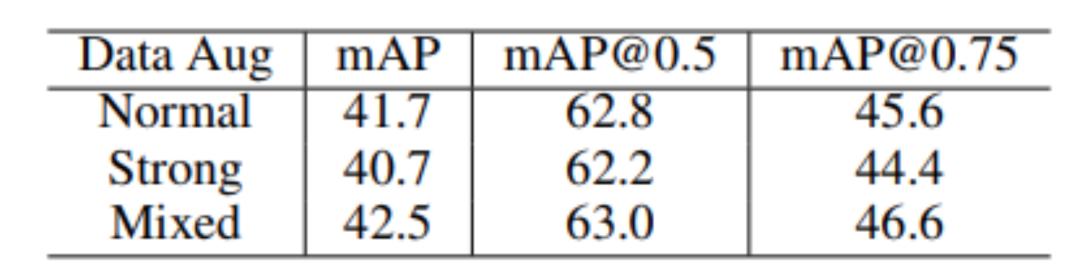
表6:对混合数据增广的消融实验
与此同时,研究员们还发现 MixTraining 可以在更长的训练轮数中获得更大的收益,结果如表7所示。
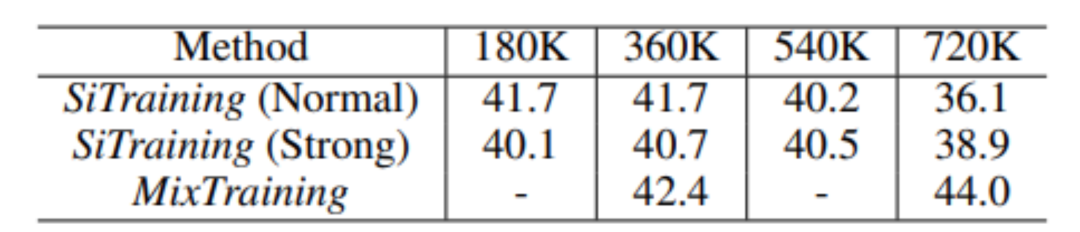
表7:MixTraining 可以在更长的训练轮数中获得更大的收益
05
自我挖掘——视频问答中对样本进行孪生采样和推理

论文链接:
https://papers.nips.cc/paper/2021/file/dea184826614d3f4c608731389ed0c74-Paper.pdf
视频问答任务需要根据语言线索的组合语义获取并使用视频中视觉信号的时域和空域特征,从而生成回答。近来,在目标数据集上微调(fine-tuning)预训练模型的范式在多模态任务中取得了非常好的效果,尤其是对视频问答任务的预训练模型。这些现存的多模态学习范式,主要通过从视频中提取空间视觉信息以及运动特征来表示视频内容,并设计了不同的注意力机制(如 question-routed attention 和 co-attention 等)来整合这些特征。然而,这些多模态学习范式都存在一个缺陷:忽略了同一个视频中视频段-文本对(clip-text pair)之间的相关性,而在训练时将每一个视频段-文本对都视为是相互独立的样本。因此,这些多模态学习范式无法很好地利用同一个视频中不同样本之间丰富的上下文语义信息。
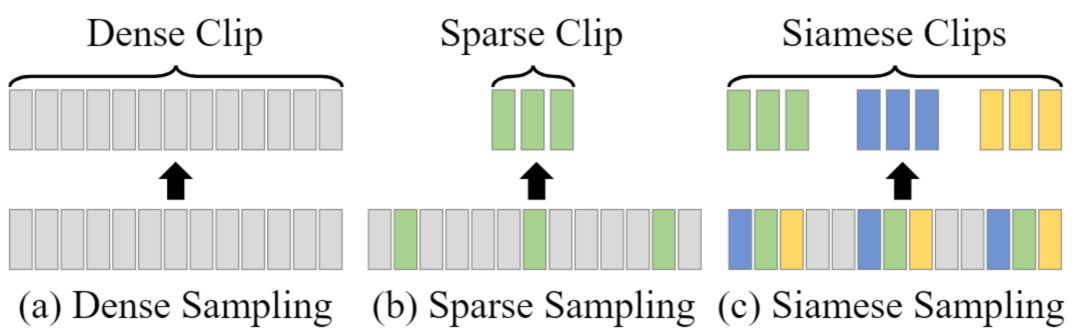
图7:不同的采样机制
为了解决上述问题,微软亚洲研究院的研究员们对如何更好地挖掘并利用这些信息进行了研究。研究员们认为,同视频中的不同视频段应该具有较为相似的全局视频特征语义以及相关联的上下文信息,并且这些信息可以被用于增强网络的学习效果。因此,研究员们提出了一个具有创新性、基于自驱动孪生采样和推理的端到端多模态学习框架 SimSamRea,能够应用在视频问答任务中。
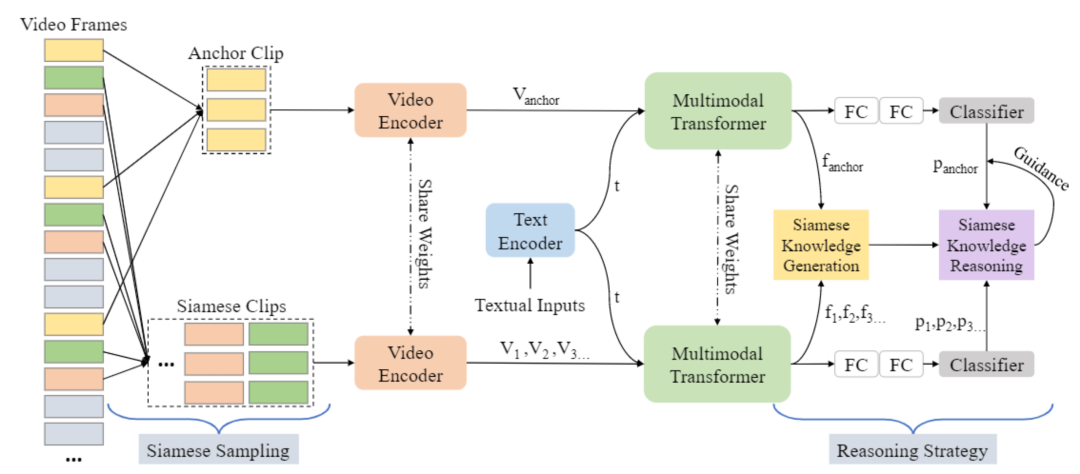
图8:SimSamRea 学习框架
在该框架中,研究员们创新地使用了孪生采样和推理,对同视频中的多个视频段信息进行融合,充分利用视频上下文信息为网络的训练过程提供指导。同时为该框架精心设计了一个推理策略,其主要包括孪生知识生成模块和孪生知识推理模块,可以预测出每个视频段所属的类别,传播并且融合基准段和孪生段之间的相关联信息,再根据模型预测出的每个视频段的类别概率为每个视频段生成软标签。研究员们以令每个视频段的软标签与其预测类别尽可能接近为优化目标,使得同一个视频中的多个视频段的语义特征尽可能相似,从而为框架的训练过程提供指导。
在五个常用的视频问答数据集上进行实验的结果显示,该方法不仅可以在训练过程中为网络提供有效的指导,而且在进行推断时没有任何额外开销(例如计算量、内存消耗、网络参数量),充分验证了 SiaSamRea 框架对视频问答任务的有效性和优越性。
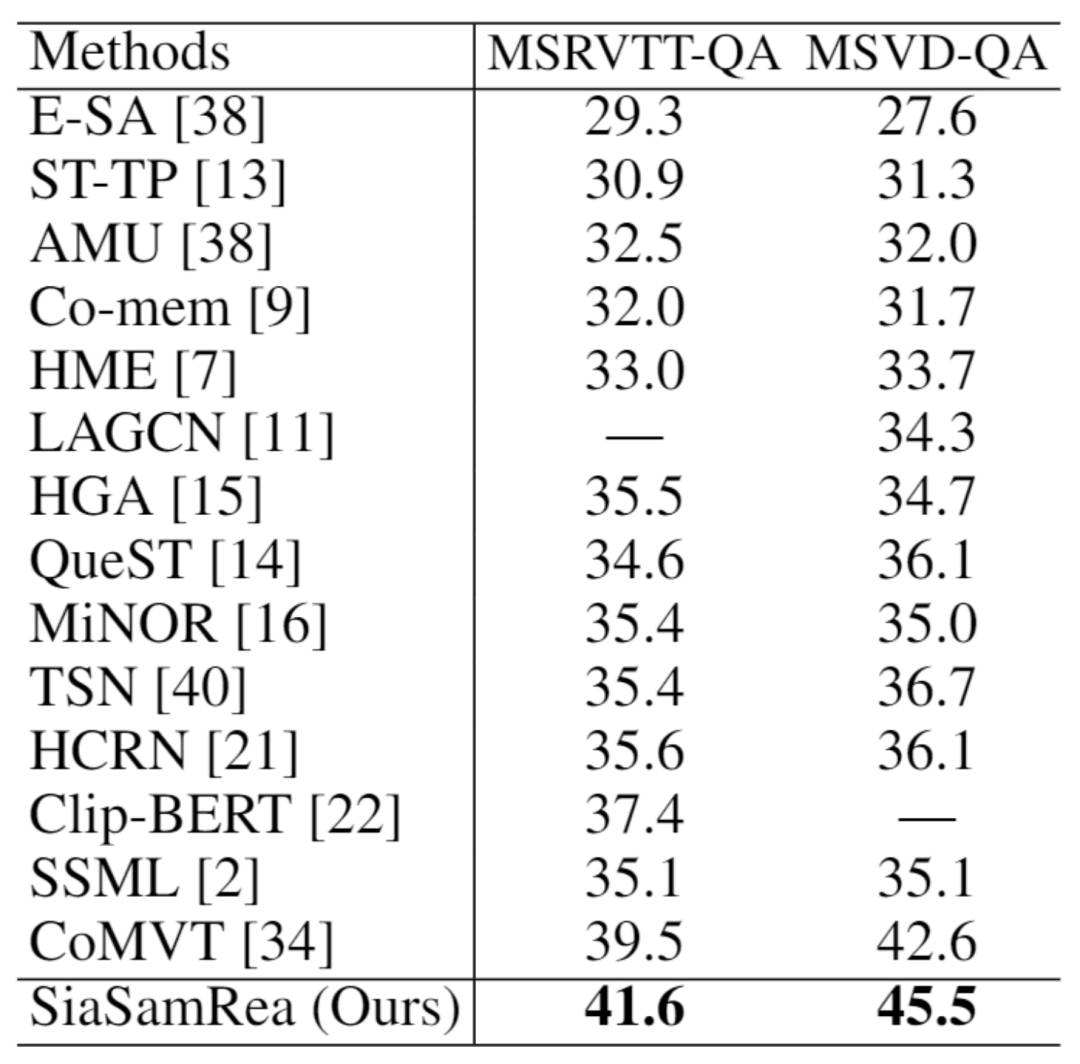
表8:不同方法在 MSRVTT-QA 和 MSVD-QA 数据集上的性能比较
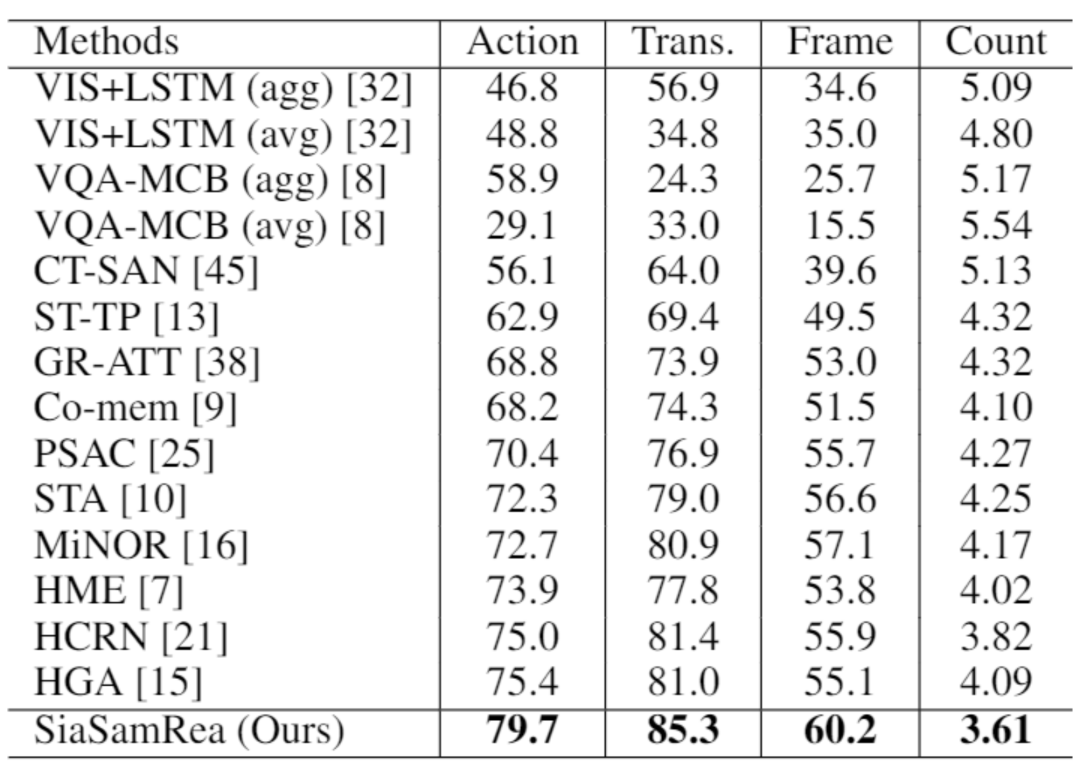
表9:不同方法在 TGIF-QA 数据集上的性能比较,Count 指标越低越好
06
去栅格化的矢量图识别

论文链接:
http://arxiv.org/abs/2111.03281v1.pdf
微软亚洲研究院的研究员们在本篇论文中,关注在一种与以往图像识别工作完全不同的图像格式——矢量图。与常用的位图不同,由于其基于解析几何的表示方式,矢量图可以被无损失地缩放到任意分辨率。同时,矢量图还提供了额外的结构化信息,描述了底层元素是如何构成高层的形状和结构。但是,现有的识别方法大多需要将矢量图渲染为像素图,再基于像素图进行识别,因此无法充分利用这一格式上的优势。
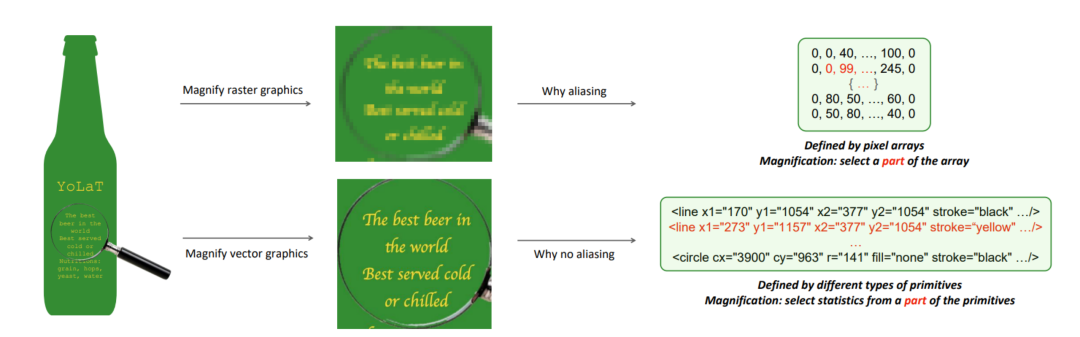
图9:矢量图和位图差异比较
本篇论文基于目标检测这一基本的视觉任务来探索这个图像格式。为充分利用矢量图的优势,研究员们提出了一种无需 CNN 的高效网络结构,在识别过程中无需将矢量图渲染为像素图(即栅格化),直接把矢量图的文本作为模型输入,称为 YOLaT (You Only Look at Text)。YOLaT 首先将矢量图转化为基于贝塞尔曲线的统一表示,并将这组贝塞尔曲线集合的结构关系建模为一个带有两组边的多重图,分表表示矢量图中元素的结构关系和空间关系。最后,研究员们提出了一个双流卷积神经网络提取图特征并进行目标检测。
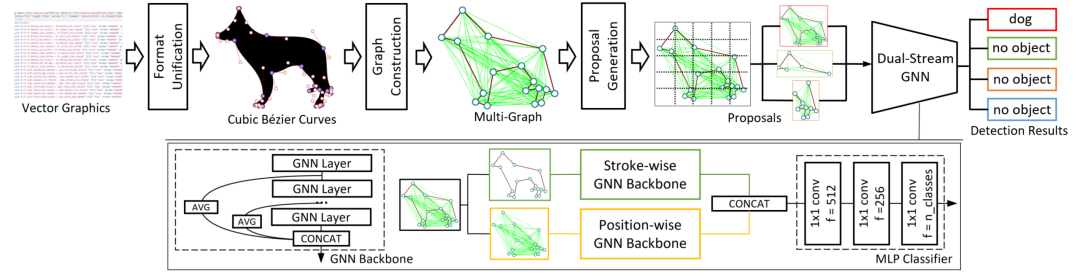
图10:YOLaT 整体算法流程
在矢量图数据集上的结果显示,相比目前 SOTA 的目标检测方法,YOLaT 在无需预训练的情况下,只需要极低的模型推理时间和参数量,就能比现有方法有显著的效果提升。
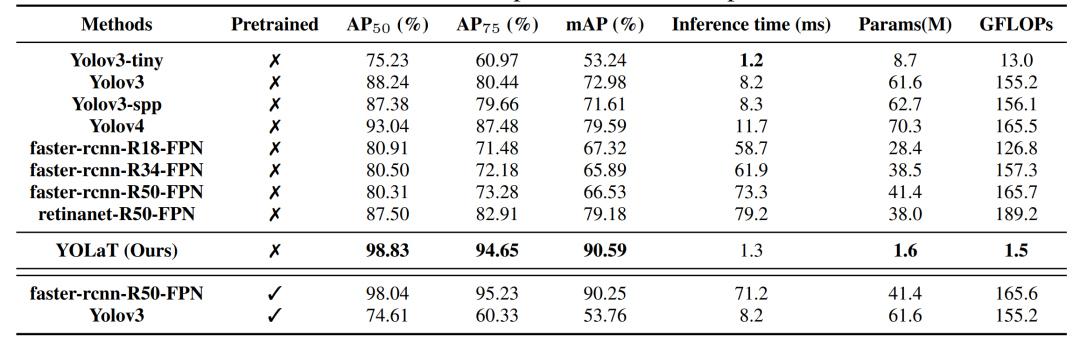
表10:在 floorplan 数据集中的性能比较
07
上亿量级规模高效向量近似最近邻搜索系统SPANN

论文链接:
https://arxiv.org/pdf/2111.08566.pdf
代码链接:
https://github.com/microsoft/SPTAG
近年来,随着深度学习的飞速发展,基于内存的向量近似最近邻搜索已经被成功地广泛应用在了语义、图片、语音等各种搜索场景,提供低延迟高召回搜索服务。然而随着数据规模的快速增长,基于内存的向量搜索面临着海量且昂贵的内存需求。因此,业界对于小内存-大硬盘混合型的向量近似最近邻搜索的需求越来越迫切。
目前业界最先进的、能够处理上亿量级规模的向量近似最近邻算法主要有两大类。一类是基于倒排索引的向量索引方法。例如:IVFADC 将整个向量空间聚成 K 个类,对每个查询只搜索和查询向量最近的一小部分类里的向量。这类方法的好处在于可以保证每个点都可达,但由于倒排表的大小非常不均匀,把倒排表存储在硬盘里容易造成一些查询存在大延迟或者低召回的问题。因此,目前大部分基于倒排索引策略的算法都采用的是将向量用乘积量化的方法进行压缩之后与只存储向量序号的倒排表一起放入内存中来加速查询效率。但是,这样则会导致召回率变差,top-1 召回率最高只能达到60%,而通过搜索多于10倍的结果进行重排序来提升召回率的方法则面临着额外开销。
另一类目前效果比较好的是基于近邻图的索引方法。例如:DiskANN 在全集上构建了一个大的近邻图,然后从一些固定的中心节点开始进行最近优先的图遍历。为了减少内存开销,这类算法通常将图存储在硬盘上,将乘积量化压缩后的向量以及最频繁访问的上层图节点存储在内存中,从而能在一些均匀分布的数据集上取得低延迟高召回的效果。然而,在一些来自真实产品的分布不均匀的数据集上,该方法则很难在有限的边集限制下保证整个图的连通性,导致一些查询的效果较差。
因此,如何在各类大规模数据集中保证低内存开销,低延迟和高召回率仍然是一个算法设计上的挑战。另外,当数据规模进一步扩大,如百亿量级网页搜索应用,搜索系统的可扩展性也面临着很大的挑战。传统的基于数据分片的分布式搜索系统需要将每一个查询都分发给每一个数据分片所在的机器进行本地查询,然后汇集每个分片上的结果进行进一步筛选返回给用户(如图11所示)。这会导致查询延迟和资源开销会随着机器数量的增多而变大,系统可扩展性变差。
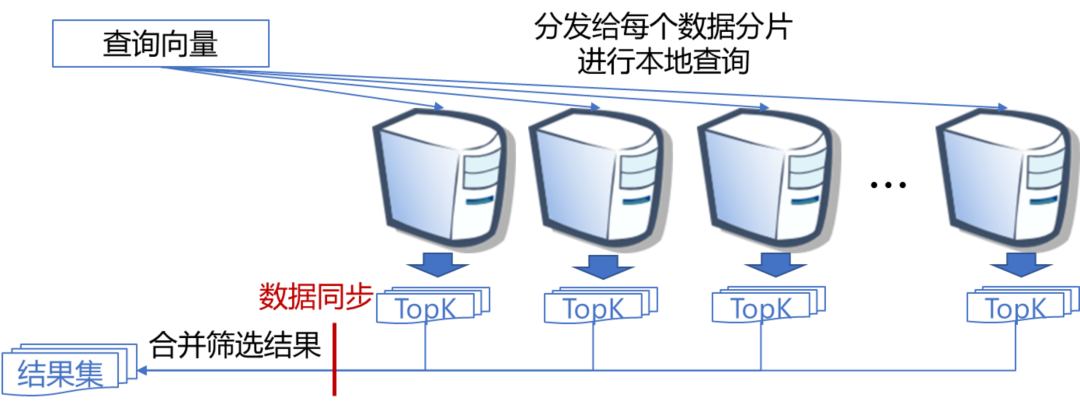
图11:基于数据分片的分布式搜索系统
基于此发现,微软亚洲研究院的研究员们提出了一种非常简单且高效的基于倒排索引思想的内存-硬盘混合型索引和搜索方案 SPANN(如图12所示),有效解决了倒排索引方法中的三个会导致高延迟或者低召回的难题:1)倒排表大小不均匀;2)最近倒排表覆盖率不够;3)查询难度差异过大。SPANN 将倒排表的中心节点存储在内存中,而将巨大的倒排表存储在硬盘上,并且有效地限制了倒排表的长度,提升了倒排表的质量和覆盖率,进而根据查询难度动态地合理剪枝。
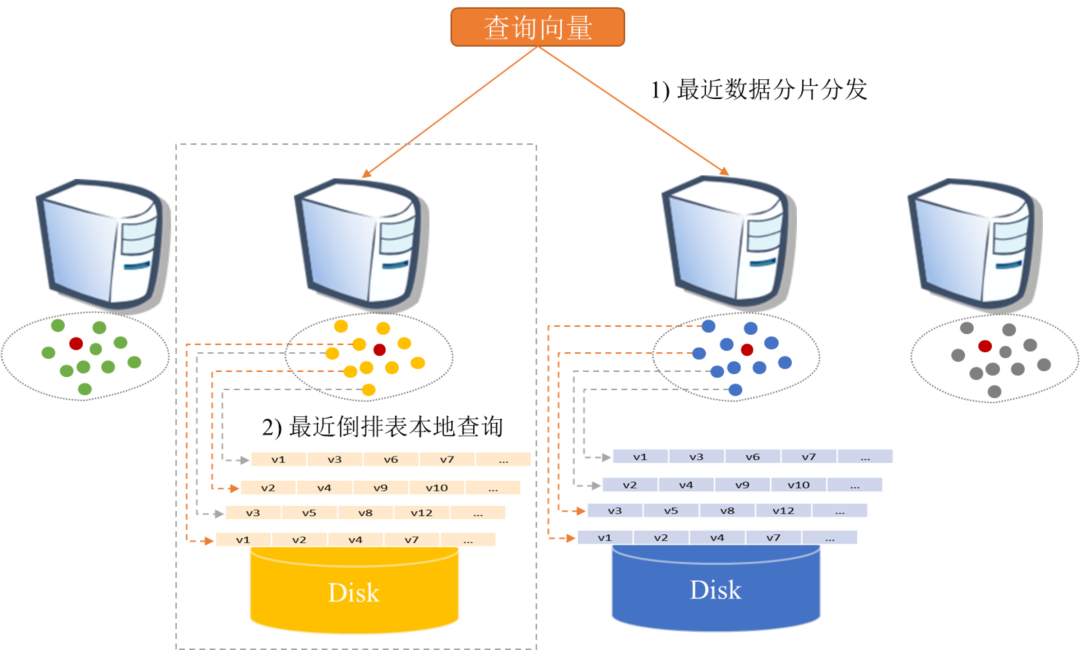
图12:SPANN 系统和算法架构
SPANN 能够极大地减少硬盘访问,从而保证低内存开销,低延迟和高召回。图13的实验结果显示,内存相同的情况下,SPANN 在多个上亿量级的数据集上都能取得两倍多的加速达到较高的90% top-1和 top-10召回率,其查询延迟都能够有效控制在一毫秒左右。同时,在分布式分发和本地搜索中同时应用 SPANN 的设计能够有效限制每个查询的资源开销和延迟大小,从而实现高可扩展的分布式搜索系统。目前 SPANN 已经被部署在了微软必应搜索中支持百亿量级的高性能向量近似最近邻搜索。

图13:SPANN 与目前最先进的基于近邻图的内存-硬盘混合方案 DiskANN 的效果对比
参考文献
[1]Zhu J, Cui Y, Liu Y, et al. Textgnn: Improving text encoder via graph neural network in sponsored search[C]//Proceedings of the Web Conference 2021. 2021: 2848-2857.
[2]Li C, Pang B, Liu Y, et al. AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search[J]. arXiv preprint arXiv:2104.12080, 2021.
[3]Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 1025-1035.
[4]Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.

NeurIPS 2021 论文分享会 Part1

NeurIPS 2021 论文分享会 Part2

NeurIPS 2021 论文分享会 Part3
你也许还想看:



关键词
模型
arxiv.org
性能
模块
论文链接
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。