爬虫基础入门

为什么要学习爬虫
其实我们身边到处都是爬虫的产物,比如我们经常用的Google,百度,bing等,这些搜索引擎就是根据你的需求在网上爬去相关的网页;比如你想在淘宝上买一个东西,可是又纠结店家是不是要价太高,这是你就可以爬去相关商品的价格,做一个对比即可;就拿咱们人工智能方向来说吧,哪个不是通过庞大的数据产生的,那这些数据怎么来的?当然就是网上爬去的啦。
先了解什么是HTML,CSS,JavaScript
因为网页基本都是由HTML组成。HTML是标签但不能算是编程语言,通过浏览器识别标签来呈现出不同的网页内容;CSS是HTML的花匠,让枯燥的原始网页变得花样多彩;JavaScript可以使HTML具有更加复杂的机制的脚本语言。
从最简单的爬虫讲起
一般python都自带urllib库,毕竟python还是以爬虫出名的吧。上代码解释:

从urllib.request中导入urlopen,然后读取网页.read( )即可,如果有中文,记得decode下。
输出的为一个网页源代码( 内容太多,截取部分 ):

然后就是通过正则表达式re匹配即可,下面是获取这个网页的title(如果对正则表达式不熟的,可以往上翻4个推送就到了):

其中re.DOTALL表示有多行的时候,要写上这个
输出的就是
因为网页里的连接都在'href='后面,所以如果想找到这个网页里的所有链接,代码为:

输出截图( 截取部分 ):

这就是最简单的爬虫。
BeautifulSoup
安装

如果是python2,3都有的话,python3+的就用pip3就行。后面的4或许是版本吧。
简单使用
先把上面得到的html喂给它,然后就想咋地咋地了。HTML里有很多标签,比如h1,这里获得h1的信息贼简单:

输出为( 部分 ):

现在说说里面的参数,features:解析器的意思,怎么选择官网解释如下:

总之就是能用'lxml'就用。
如果想查找所有呢:

输出(部分):
但是我们想要的是'href='后的链接,这里hrefs相当于字典,因为'href'是a标签的以一个属性,可以把'href'当做key来查找:

结果为( 部分 ):
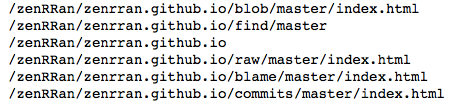
Beautifulsoup: find by CSS class
这里我就用morvan的教程网页了。
HTML一般都会和CSS一起搭配,所以有时候的数据选取会和CSS有关,总之CSS你只要知道它的class即可,根据class爬取数据。
我们先读取它的文本:

大概样子为:
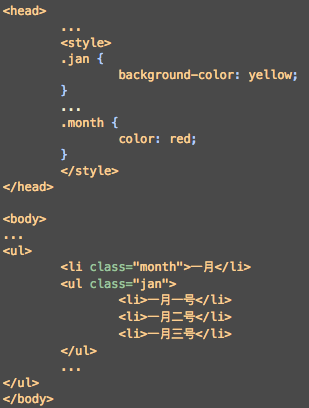
CSS一般可能在<head>...</head>里。很明显CSS归类的这些组件还是很有用的,比如我们就想找class="jan"下面的<li>...</li>里面的内容。而且Beautiful Soup就能这么干。上代码:

也可以先获得<ul>...</ul>,在获得里面的<li>...</li>:
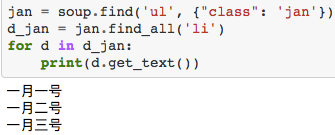
BeautifulSoup解析网页:正则表达
先看看这次的教程的示例网页:

比如你想下载这个页面的图片,我们先通过BeautifulSoup筛选它们,然后通过正则表达提取。

也就是通过查找标签为img,并且属性src符合 的链接。
的链接。

获取'href'链接也一样:

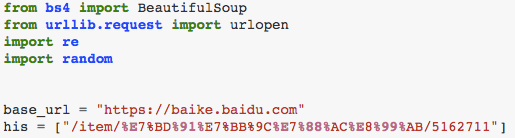
小练习:爬取百度百科
任务是模仿类似深搜的方法,爬取当然网页任意一个的百度百科词条。

his 是history,存取以往的url,his后面的值就是'网络爬虫'的具体地址。
先打印一下试试:

但是有的sub_urls没有符合要求的网页,这时候就需要向前跳一个,继续爬取。又因为百度百科词条的HTML大致满足这个要求:

则,代码为:

结果为:

在此感谢莫烦教程。良心推荐:如果想具体了解莫烦的其他教学,点击原文链接。
欢迎转发和关注深度学习自然语言处理公众号

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。