过拟合解决方法之L2正则化和Dropout
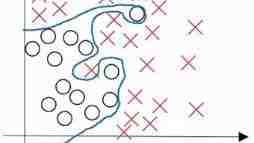
什么是过拟合?
一幅图胜千言万语
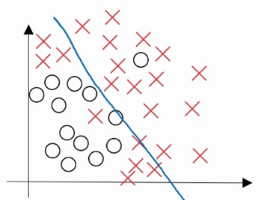
欠拟合
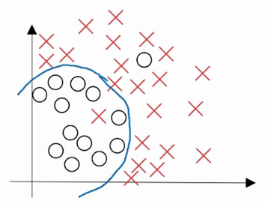
正确的拟合
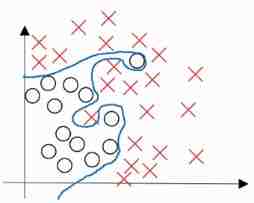
过拟合
过拟合(overfitting):就是对数据的过度严格的拟合。这个经常出现在分类问题上。
怎么解决过拟合呢?
L2正则化
逻辑回归 中L2正则化的过程:
L2正则化是最常用的正则化。
我们先求出代价方程J(w,b)为:

L2正则化,就是在代价方程后面加个lambda/(2m)参数W范数的平方,下标2表示L2正则化的意思,2是为了接下来的求导好化简而写的,就是个比值而已:
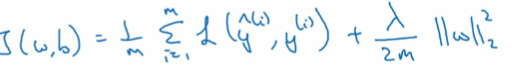
其中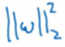 是:
是:
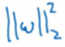
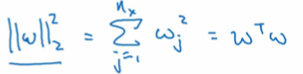
但是为啥参数W都用上了,为啥不+bias b:
因为,b也是一个参数,而且是一个数,而W是很多个参数,感觉少了b也没啥所以一般不写上b。
这里的 是超参数,跟学习率一样,需要我们自己设置。
是超参数,跟学习率一样,需要我们自己设置。
神经网络 L2回归的过程:
神经网络其实就是有大于等于1个隐藏层,也就是比逻辑回归多了参数而已:
其中 为:
为:

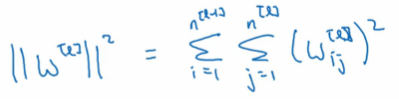
注:L-1=上一层的大小,L是当前层的大小
该矩阵范式被称为Frobenius norm 即弗罗贝尼乌斯范数,表示为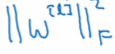 即:
即:
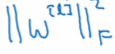

这个矩阵L2范式,也叫弗罗贝尼乌斯范数。
求导:
没有L2正则化以后,导数是这样的,[from backprop: 从反馈传播求得的]:
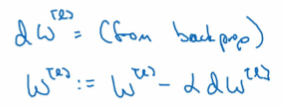
而现在有了L2正则以后,就变成了:
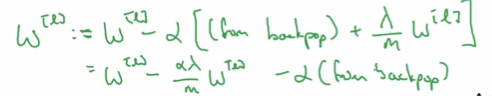
其中可以看出和上面的原本的W^[L]比,缩小成了下面的倍数(其中alpha>1):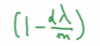
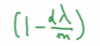
这个W的缩小的变化使得L2正则化被称为“权重衰退”。
有L2正则化就有L1正则化,但是为啥不用呢?
L1正则化的||W||为:

L1的正则化的||W||会使得W最终变得稀疏,也就是有很多0出现,有助于压缩参数和减小内存,但这也不是我们用L1正则化的目的,不是为了压缩模型。(这个斜体加粗的话我还没弄懂为啥会出现很多0,知道的小伙伴分享下)
Dropout
Dropout有很多,其中Inverted Dropout反向随机失活最常用。根据这个翻译的意思,也能大概猜出来Inverted Dropout的意思,也就是从后面随机使一些当前层的神经单元失效。
上图说话:
没Dropout前的网络为:
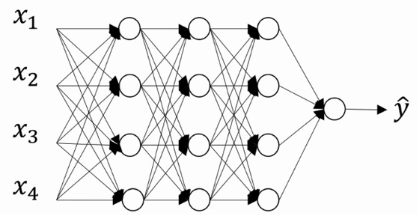
开始Dropout操作:
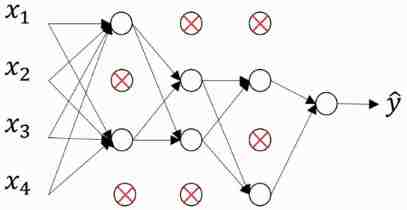
注释:红叉的单元是被去除的,也就是该单元权重置为0。
这个dropout操作是从最后一层开始的,首先需要设置一个值,keep_prob,就是保留多少,范围0-1。这个例子很明显是0.5。然后在从后往前经过每一层,都把当前层随机流线keep_prob的比例,其他的单元的权重置为零。
代码模拟实现为:
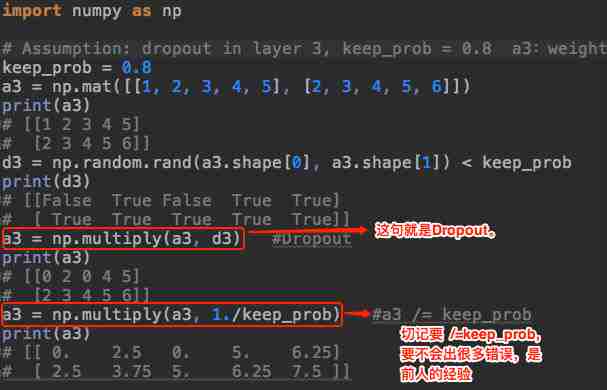
感谢Andrew Ng的视频!
欢迎关注深度学习自然语言处理公众号

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。