白话 IT 之 从 Hive 到 Presto 到 Airpal

致谢:感谢好友曾洪博(Airbnb Data Infra Engineer)帮忙审稿。
前言
随着基于 Hadoop 的大数据处理越来越广泛,在 Hadoop 上对数据进行 SQL 查询的操作也成为各个公司最常用的应用之一。本篇主要介绍一个由 Facebook 开源的快速交互式SQL搜索引擎 Presto。将他和大家熟悉的 Hive 进行一个很简单的比较。最后略提 Airbnb 基于 Presto 的一个开源项目 Airpal。
Hive:基于 MapReduce 的批处理查询
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。这个框架上已经集成了很多的子项目,帮助用户在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop 作为一种分布式数据和计算的框架,可以想象,它的子项目的核心技术,就包括对数据的存储、计算和查询 。最早纳入 Hadoop 项目的一些核心技术,就包括 HDFS 和 MapReduce。简单来说,HDFS为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
而 Hive,就是建立在 Hadoop 上的数据仓库基础构架。他支持对存储在 HDFS 以及其他兼容的文件系统如 Amazon S3 文件系统上的数据的查询和分析。Hive 也是一个基于 MapReduce 的计算框架,它提供了一个类似 SQL 的叫做 HiveQL 的语言,可以对有 schema 的结构化数据进行读取,并将 query 转化成 MapReduce 任务来进行查询。
HDFS、MapReduce、和 Hive 是大家最常见的 Hadoop 上和数据处理相关的项目,很多人已经很熟悉。由于基于 Hive 的 HQL 是把 SQL 转换成 MapReduce 任务来完成的,通常因为作业提交和作业调度需要大量的开销,所以 HiveQL 查询的延迟极高,一个简单的查询也往往有几分钟的延迟。所以 Hive 更实用于大数据集的批处理作业,比如网络日志分析。然而对一些需要频繁操作的实时查询,或者需要低延时的应用,Hive 的效率就太低。
Presto:快速交互式SQL搜索引擎
Presto 是 Facebook 从 2012 年末开始开发的一个分布式 SQL 引擎,用 Java 写的,已开源。现在 Dropbox 和 Airbnb 也在使用。主要解决的问题就是工程师和数据科学家每天需要交互式的对数据仓库中数据做一些即时的查询,延时太大会极大的影响工程师和数据科学家的工作效率。
使用 Presto 对 数据进行 SQL 查询具有以下特点:
- 与 Hive 的批处理不同,Presto 主要用于低频的,随机的,交互式查询。
- 语法与 ANSI SQL 极为相似,但略有不同。
- Presto 的实现和 Hive 有着本质的不同。Hive 是把一个 query 转化成多个 stage 的 MapReduce 的任务,然后一个接一个执行。执行的中间结果通过对磁盘的读写来同步。Presto 没有使用 MapReduce,它是通过一个定制的 query 和执行引擎来完成的,参见《Presto: Interacting with petabytes of data at Facebook》(链接1)。
- Presto 所有的查询处理是 in memory 的,这也是它性能很高的一个主要原因。所以在日常使用中,如果有大量的 join 偶尔会发生内存不足的报错,一个常见的解决方法是生成中间表的方式来减少 join 的次数。
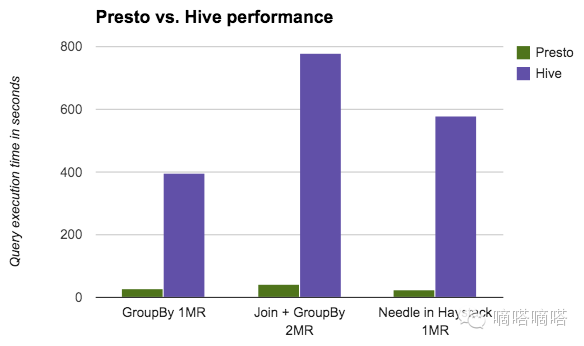
- Presto 比 Hive 的性能好很多,尤其适合做 needle in haystack 这样的 key lookup 操作。有些操作 Hive 可以 run 几小时而 Presto一分钟就能搞定:
- Presto 支持多种存储系统和文件结构。存储系统的支持包括 HDFS,HBase,Scribe 等。文件结构的支持包括 Jason,Avro,Parquet,RCFile,ORCFile 等。《Using Presto in our Big Data Platform on AWS》(链接7)一文中,对 Presto 对于不同文件格式的查询性能做了一个比较。可以看出,Presto 对非结构化的数据查询效率最低,对 RCFile 或 ORCFile 的查询性能最高:

Airpal:基于 Presto 的 web 查询接口
Airpal 是 Airbnb 2015 年开源的一个基于 Presto 的 SQL 查询引擎。其最大的区别,就是提供了一个可视化的 web 界面,让数据查询变得更直观和高效:
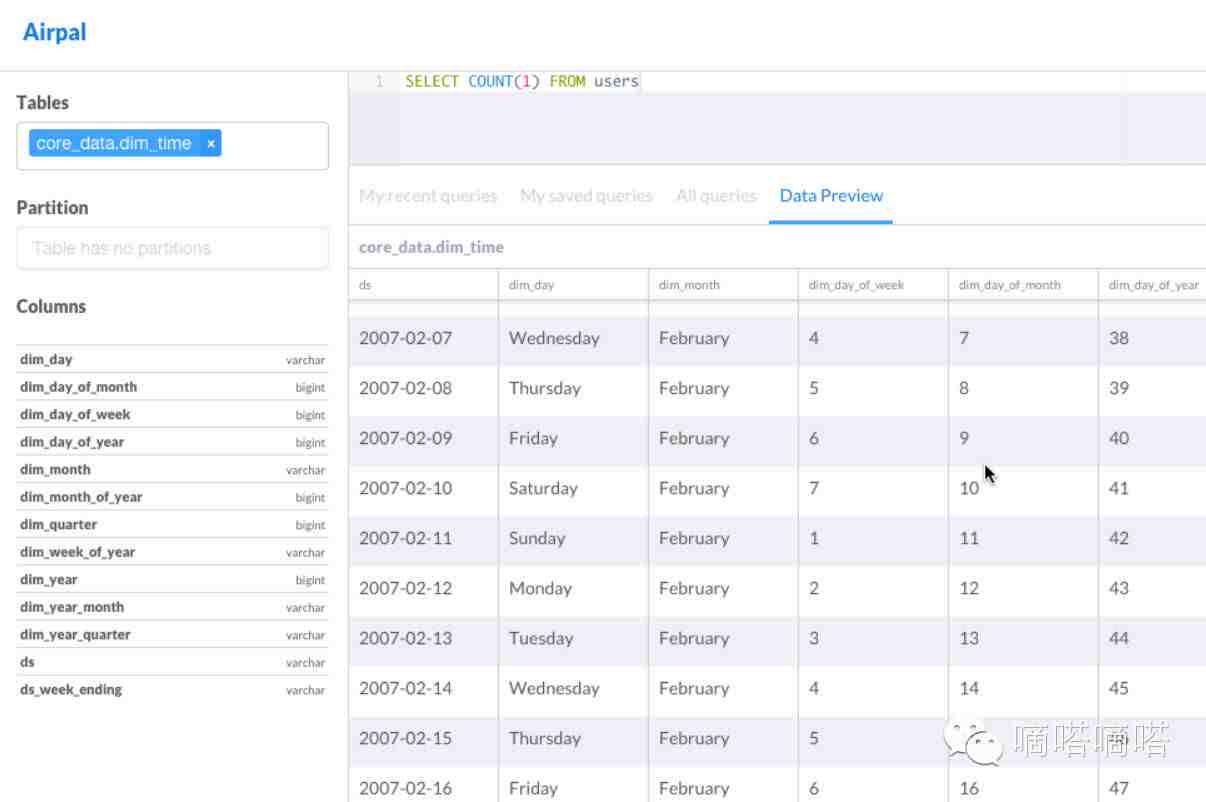
Airpal 比 Presto 的用户体验要更人性化,包括:
- 可以简单的在 metadata, partitions, schemas, 和 sample rows 之间进行 tab 切换。
- 易于复制粘贴修改的 query 编辑器。
- 有一个进程条来跟踪查询的进度。
- 可以把结果以 CSV 格式下载
- 可以保存一个 query,或者从 query 历史中选择一个 query 来执行。
- 与 LDAP 关联,设定用户访问权限。
该开源项目的介绍和 github 参见《Introducing Airpal》(链接9)
链接及相关阅读:
- 《Presto: Interacting with petabytes of data at Facebook》:https://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/10151786197628920/
- 《8 SQL-on-Hadoop frameworks worth checking out》:http://blog.matthewrathbone.com/2014/06/08/sql-engines-for-hadoop.html
- 《Presto: Facebook’s Distributed SQL Query Engine》:http://www.infoq.com/news/2013/11/Presto
- 《Even faster: Data at the speed of Presto ORC》:https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
- 《Faster Big Data on Hadoop with Hive and RCFile》:http://www.semantikoz.com/blog/faster-big-data-hadoop-hive-rcfile/
- 《ORC: An Intelligent Big Data file format for Hadoop and Hive》:http://www.semantikoz.com/blog/orc-intelligent-big-data-file-format-hadoop-hive/
- 《Using Presto in our Big Data Platform on AWS》:http://techblog.netflix.com/2014/10/using-presto-in-our-big-data-platform.html
- 《Presto-as-a-Service: Interactive SQL Queries on AWS》:http://www.infoq.com/news/2014/01/presto-aws-qubole
- 《Introducing Airpal》:http://nerds.airbnb.com/airpal/
- 《Airbnb Boosts Presto SQL Query Engine For Hadoop》:http://www.informationweek.com/big-data/big-data-analytics/airbnb-boosts-presto-sql-query-engine-for-hadoop/d/d-id/1319359
注:本号谈技术,在力求准确的前提下尽量保证浅显、白话,更适合入门者阅读。按朋友的说法,属于技术入门的开胃菜。专家慎入。
讲述技术、白话硅谷。偶尔八八程序员身边的事儿。关注长按二维码:

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。