ICLR 2024 杰出论文!涨点神器!Meta提出:ViT需要Registers
点击下方卡片,关注“CVer”公众号
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!
转载自:极市平台 | 作者:科技猛兽
导读
本文提出视觉 Transformer 的特征中存在 "伪影",这些 "伪影" 会导致一些 token 的拥有很高的范数。本文提出一种有效的方案来解决 "伪影" 的问题,方法称之为寄存器 (Register),就是为视觉 Transformer 添加几个额外的 tokens。
本文目录
1 视觉 Transformer 需要寄存器(来自 FAIR, Meta)1 Register 论文解读1.1 背景:视觉 Transformer 的特征中存在 "伪影"1.2 视觉 Transformer 中 "伪影" 的特点1.3 针对 "伪影" 的假设和补救措施1.4 实验结果
太长不看版
本文提出视觉 Transformer 的特征中存在 "伪影",这个现象无论是有监督训练还是自监督训练的视觉 Transformer 中都存在。这些 "伪影" 会导致一些 token 的拥有很高的范数,这些 token 通常是在图片信息密度比较低的背景中出现,然后会参与到后续模型的计算过程中。
作者通过一系列对比实验来阐明关于 "伪影" 的一些性质,在本文的1.2小节中介绍。
本文提出一种有效的方案来解决 "伪影" 的问题,如图1所示。本方法称之为寄存器 (Register),就是为视觉 Transformer 添加几个额外的 tokens。和正常的 tokens 的不足之处是,这些寄存器的输出特征不参与到分类过程中。寄存器的功能得到了实验验证,可以:1) 使得自监督训练得到的视觉 Transformer 在密集预测任务中取得 SOTA。2) 使大一点的模型具有 object discovery 的能力。3) 使得特征图和注意力图更加平滑,有利于下游的视觉处理。
视觉 Transformer 需要寄存器
论文名称:Vision Transformers Need Registers
论文地址:
https//arxiv.org/pdf/2309.16588
1 Register 论文解读:
1.1 背景:视觉 Transformer 的特征中存在 "伪影"
本文研究的是 Vision Transformer 的特征问题。深度学习发展到今天,通常是使用大量的数据通过监督学习或者自监督学习预训练模型,把训练出来的模型作为特征提取器,允许训练强大的特征模型来解锁下游任务。基于 Transformer 架构的自监督方法,尤其是 DINO[1],因其在下游任务中的高预测性能和一些模型提供无监督分割的有趣能力,而备受关注。
DINO[1]算法所得到的模型已经被证明可以显示地得到图像的语义信息。定性的结果表明,最后一个注意力层会自然地关注到图像中的语义部分的信息,且通常会产生可解释的注意力图。利用这些属性,可以在 DINO 的基础上构建一些 object discovery 算法比如 LOST[2]。这个算法可以无监督地收集注意力图中的信息,有效解锁了计算机视觉的新前沿。
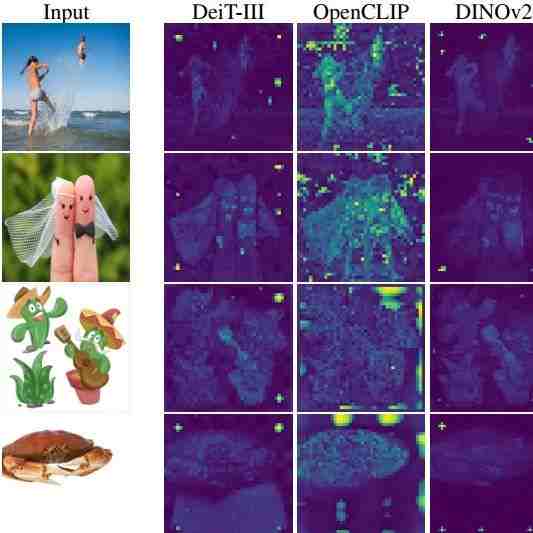
DINO v2[3]算法是 DINO 的后续工作,其得到的特征适合密集预测任务。DINO v2 在单目深度估计任务和语义分割任务中表现出色。尽管密集任务的性能很强,但作者观察到 Dinov2 与 LOST 不兼容。在这种情况下,其性能仅仅与有监督的视觉 Transformer 的性能是相当的。这一现象说明 DINO v2 和 DINO 表现截然不同,DINO v2 特征中的一些 "伪影" 在 DINO 中是不存在的。同样令人惊讶的是,对有监督训练得到的视觉 Transformer 使用相同的观察也暴露了类似的伪影,如下图2所示。这说明 DINO 是个例外,除了异常情况 DINO 外,很多视觉 Transformer 模型的特征中都会有 "伪影"。
1.2 视觉 Transformer 中 "伪影" 的特点
如上图2所示,很多现代视觉 Transformer 的特征中都会存在 "伪影",DINO 中没有伪影,但是 DINO v2 里面又有了。在本节中,作者研究了为什么以及何时出现这些伪影。
1) "伪影" 是范数值很高的异常 token。
在下图3中,作者比较了给定参考图像的 DINO 和 DINO v2 模型的局部特征范数,可以清楚地看到,"伪影" 的范数远高于其他补丁的范数。
作者还在图4中绘制了特征范数的分布,显然是双峰的。定义范数高于 150 的 token 将被视为 "高范数" token。对于 Dinov2,尽管大多数 token 的范数在 0 到 100 之间,但一小部分 token 具有非常高的范数:范数大于 150 的 token 的比例为 2.37%。
2) "伪影" (异常值) 出现在大模型的训练中。
作者对这些异常值 token 出现在 DINOv2 训练过程中的条件进行了一些额外的观察。如下图5所示,(a) 输出 token 的范数沿着 layer 的分布;(b) 输出 token 的范数随着 iteration 的变化;(c) 输出 token 的范数随 model size 的变化。从图5 (a) 可以发现,高范数的 token 与第15层的 token 不同。从图5 (b) 可以发现,高范数的 token 只出现在三分之一的训练之后。从图5 (c) 可以发现,只有3个最大的模型表现出异常值。
3) 在当前 Patch 信息冗余时,范数值很高的异常 token 出现。
为了验证这一点,作者计算了在 Patch Embedding 层之后的高范数 token 和 4 个相邻 tokens 的余弦相似度,并绘制曲线如下图6所示。可以看到,"伪影" (异常值) 出现时与周围相邻 tokens 的余弦相似度高的 tokens 所占得比例很大,说明这些 tokens 包含冗余信息,并且模型可以在不损害图像表示质量的情况下丢弃它们的信息。这个结论也和图2的定性观察匹配,即 "伪影" 一般出现在图片的背景区域中。
4) 高范数值异常 token 几乎不包含局部信息。
为了更好地理解这些标记的性质,作者探索了不同类型信息的 tokens,设计了两种不同的任务:位置预测和像素重建。做法是训练一个 Linear Model 来完成这些任务,并观察模型的性能。
位置预测
做法:训练一个 Linear Model 来从 Patch Embedding 中预测图像中每个 Patch 的位置,并测量其准确性。位置信息以绝对位置嵌入的形式在第一个 ViT 层之前的 token 中注入。作者观察到高范数 token 的准确度远低于其他 tokens,这表明它们包含有关它们在图像中的位置的信息较少。
像素重建
做法:训练一个 Linear Model 来从 Patch Embedding 中预测图像的像素值 (Pixel Value),并测量该模型的准确性。作者再次观察到,高范数 tokens 比其他 tokens 实现了更低的准确度。这表明高范数 tokens 包含的信息比其他标记少。
5) "伪影" (异常值) 保留了全局信息
为了评估在高范数 token 中收集了多少全局信息,作者在评估了它们学习表征的能力。对于分类数据集中的每张图片,作者将其通过 DINO v2-g 模型提取 Patch Embedding,并且进一步使用这个 Patch Embedding 来识别图片的类别,就是做一个分类任务。实验结果如图8所示,可以观察到高范数 tokens 比其他 tokens 具有更高的精度,这表明异常值标记比其他 Patch Embedding 包含更多的全局信息。
1.3 针对 "伪影" 的假设和补救措施
在上面的1.2小节中,作者通过一系列对比实验来阐明关于 "伪影" 的一些性质,并给出了假设和补救措施。
这个假设是:经过充分训练的大模型学习去识别冗余的 tokens,并将它们用来存储,处理和检索全局位置的信息。作者假定这种行为模式本身并不坏,但是对于模型的输出如果包含这种 tokens 就不太可取。事实上,这种异常的 tokens 会引导模型丢弃局部的信息,导致密集预测任务性能的降低。
因此,作者提出了一个简单的方法来解决这个问题:对 ViT 模型显式地添加一些新的 tokens,它们可以用来作为寄存器 (Registers)。它们类似于 [CLS] token,具有可学习的值。在 ViT 的输出层,这些 tokens 被丢弃了。[CLS] token 和其他正常的 image tokens 不丢弃,这点和 ViT 是一致的。这一点最早在 NLP 任务中[4]被提出。有趣的是,作者在这里表明这种机制也适合视觉 Transformer,且在可解释性和性能方面给出了其他一些见解。
1.4 实验结果
作者在本节中对 [reg] token 的作用做了实验评估:作者对其数量做了消融实验研究,以及对其学习到的特征进行了定性的分析。作者使用的验证方式有:
有监督方法 DEIT-III[5]:是一种简单而有效的监督训练方法,用于在 ImageNet-1k 和 ImageNet-22k 上使用 ViT 进行分类。它很简单,而且使用基本的 ViT 架构,实现了强大的分类结果。作者使用的数据集是 ImageNet-22K,模型是 ViT-B,遵循的代码是[6]。
文本监督方法 OpenCLIP[7]:文本图像对齐模型的强大训练方法,遵循原始的 CLIP 方法。它是开源的,使用基本的 ViT 架构,并且很容易复现以及修改。作者使用的数据集是 Shutterstock,模型是 ViT-B/16 image encoder。
自监督方法 DINO v2[3]:学习视觉特征的自监督方法,遵循 DINO 方法。作者使用的数据集是 ImageNet-22K,模型是 ViT-L,遵循的代码是[8]。
实验结果如下图9所示,在使用了 [reg] tokens 之后,"伪影" 消失了。注意力图也变得像 DINO 一样更加可解释了。从图10中可以看到,当使用 [reg] tokens 进行训练时,模型在输出处没有表现出高范数的 tokens,这证实了最初的定性评估。
下面是作者在 ImageNet classification, ADE20k Segmentation, 和 NYUd monocular depth estimation 任务上的 Linear Probing 结果,实验结果如图 11(a) 所示。使用 [reg] 时,模型不会丢失性能,有时甚至效果更好。为了完整起见,作者还提供了 OpenCLIP 的 ImageNet 上的零样本分类性能,实验结果如图 11(b) 所示。
作者还进一步对 [reg] tokens 的数量作了消融实验。如下图12所示,可以观察到,当添加至少一个 [reg] token 时,可见的 "伪影" 就消失了。
如图13所示是 ImageNet, ADE-20k 和 NYUd 下游任务实验结果。对于密集预测任务,似乎有最佳数量的 [reg] tokens 数量,这个最优值似乎可以通过 "伪影" 的消失来解释,从而获得更好的局部特征。在 ImageNet 上,当使用更多寄存器时,性能会提高。在作者所有的实验中都保留了 4 个 [reg] tokens。
作者最后定性地探讨了 [reg] tokens 的行为,想验证它们是否都表现出相似的注意力模式,或者不同的 [reg] tokens 的模式有哪些不同,[CLS] token 和 [reg] tokens 的注意力图的可视化结果比较如下图14所示。可以看到,[reg] tokens 之间没有完全对齐的行为模式,一些选定的寄存器表现出有趣的注意力模式,关注场景中的不同对象,这种自然的多样性很有趣。
参考
1.Emerging properties in self-supervised vision transformers
2.Localizing objects with self-supervised transformers and no labels
3.DINOv2: Learning Robust Visual Features without Supervision
4.Memory Transformer
5.Deit iii: Revenge of the vit
6.https://github.com/facebookresearch/deit
7.https://github.com/mlfoundations/open_clip
8.https://github.com/facebookresearch/dinov2
何恺明在MIT授课的课件PPT下载
何恺明在MIT授课的课件PPT下载
CVPR 2024 论文和代码下载
CVPR 2024 论文和代码下载
Mamba、多模态和扩散模型交流群成立
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

 ▲扫码加入星球学习
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。