今日arXiv最热大模型论文:复旦提出基于diffusion的虚拟试衣模型,模特一键换装

夕小瑶科技说 原创
作者 | 谢年年
仅需上传模特图像,便可一键换装,极大提高了用户网购衣服的效率。
虚拟试衣(Virtual Try-On)作为图像生成中一个商业价值高、可以直接变现的子任务,研究热度随着图像生成技术的发展水涨船高。
但现有的一些方法生成的效果还差点意思,如下图所示:
基于GAN的方法换装后与模特不贴合,像是简单粗暴P上去的一样。扩散模型的出现使其可以生成逼真的试穿图像,但它们往往在细节上还原度不高,比如衣服的色彩版型与原始平装衣物不一致。
复旦团队认为扩散模型的随机性和潜在监督不足是导致问题的关键因素。为了缓解这些问题,作者为虚拟试衣(VTON)任务提出了一种新颖的忠实潜在扩散模型——FLDM-VTON。
该方法在传统的潜在扩散过程的训练中从两个主要方面进行了改进:(i) 通过利用变形后的衣物作为起点和局部条件,提供忠实的衣物先验,以减轻初始和过程中的随机性,(ii)通过一个新颖的衣物平坦化网络,从原始平装衣物引入额外的图像级约束。结果显示,FLDM-VTON在性能上超越了最先进的基线,能够生成具有真实照片级逼真度和忠实衣物细节的试穿图像。
论文标题
:
FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on
论文链接
https://arxiv.org/pdf/2404.14162.
:
https://arxiv.org/pdf/2404.14162.
方法概览
带有衣服先验的扩散模型
给定一个人像图像 和一个表示试穿区域的掩码 ,可以通过逐元素乘法得到一个无衣物的人像 ,表示试穿区域被遮罩的人像。虚拟试穿(VTON)的目标是将一件平铺的衣物 转移到 上,生成逼真的试穿图像,并保持衣物的细节。
以往的方法采用LDM 通过预训练的编码器 和解码器,在潜空间中训练一个扩散模型,包括前向和反向过程。在前向过程中,会在任意时间步向结果的潜在特征 中添加高斯噪声,其中 是真实试穿图像。在反向过程中,使用扩散 U-Net 估计添加的噪声 。
传统的方法能产生逼真的效果,但在衣服细节的处理上还不够完善。因此本文以 或变形衣物特征 作为起点,其中变形衣物特征在开始时提供了衣物先验。将 称为主起点,称为先验 起点。此外,利用预变形的试穿图像特征 作为所有时间步的先验局部条件,其中 。
前向过程
在主起点 和先验起点 z_0^p 的潜在特征上逐渐添加高斯噪声 t$,得到对应的 t-阶潜在特征。如下公式所示: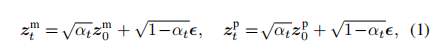
反向过程
将缩小的掩码 作为去噪条件,预扭曲的试穿图像特征 作为局部先验条件。我们将第个潜在特征、局部先验条件和去噪条件沿通道维度连接,作为扩散 UNet 的输入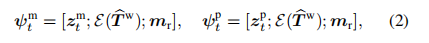
对于一对图像,可以得到两个不同的输入:主噪声输入 和先验噪声输入。这些输入分别通过相同的试穿扩散 UNet U 进行处理,以预测主初始潜在特征 。还会通过 DINO-V2 (一个当前强大的无监督视觉编码器 V)对平铺的衣服进行编码,作为全局控制器,通过跨注意力注入到每个 UNet层中。因此,单个样本和时间步的扩散训练损失函数定义为:
衣物一致的忠实监督
在真实试衣时,当用户脱下并展开试穿的衣服时,它应与平铺的衣物完全相同。为此,作者设计了一个衣物展开网络,它可以从生成的试穿图像中移除衣物并使其像原始平铺衣物一样展开,可进一步提高衣服细节度。
该网络包含两个步骤:脱下与展开。脱下通过使用预分割的衣物掩码 对生成的试穿图像进行遮罩来完成。
展开步骤是一个反向映射过程,训练一个展开模块来预测展开流。展开网络采用 U 型结构,利用特征金字塔网络(FPN)在多尺度上编码衣物分割特征,然后使用级联的流估计块,根据缩小的平铺衣物位置掩码预测展开流,如下图所示。使用混合损失函数训练衣物展开网络,包括图像级别的 损失和感知损失 ,以及流级别的二阶平滑损失 和梯度总和损失 ,定义为
整体架构
整体FLDM-VTON的整体架构如下图所示。
训练阶段
处理每个样本时,首先通过将t-th潜在特征与先验局部和去噪条件拼接,得到主要输入和先验输入。然后,试穿扩散UNet U 在全局控制器DINO-V2 V 的指导下,分别处理这两种类型的输入,利用扩散损失估计试穿的潜在特征。此外,FLDM-VTON还包含一个衣物平整网络,通过衣物一致损失提供衣物一致的忠实监督。试穿扩散UNet的总体训练损失定义如下:
推理阶段
在引入衣物先验进行模型训练后,FLDM-VTON可以从一个特定条件于变形衣物特征的后
验高斯噪声开始推理。具体来说, 衣物后验噪声是第T步先验潜在特征:
通过这种方式,采样过程的初始随机性显著降低,确保生成的衣物细节的还原度。
实验
定量比较
下面两个表分别展示了在两个基准上的效果,显示了在配对和无配对设置下,FLDM-VTON在各种性能指标上优于大多数基线。
定性比较
作者还导出了不同模型换装后的效果,从多个例子中可以看出FLDM-VTON在生成逼真的试穿图像的同时,能还原衣服的细节。
作者还将该模型应用于来自亚马逊网站的现实世界数据,FLDM-VTON具有很强的稳健性
作者进一步通过简单地遮盖与源衣物和目标衣物相关的区域,对FLDM-VTON进行了更具挑战性的试穿情况测试。如下图所示,FLDM-VTON同样展现出强大效果。
消融实验
作者以传统的无条件修复的LDM作为初始基线,如下表所示。
首先,通过添加预设的局部条件 进行增强。由于扭曲衣服提供的先验信息,生成的试穿图像能捕捉到大部分粗粒度的服装细节。然而,复杂图案的风格却显著失真。
其次,通过整合CLIP或DINO V2的全局条件,这些复杂图案的风格有了显著提升。值得注意的是,DINO V2优于CLIP,这归功于其更具区分性的全局特征提取能力。
然后以带有预设局部条件和DINO V2全局条件的修复LDM作为初始基线。首先,通过加入对预设去噪输入的额外训练这个过程,复杂图案的风格得到了很大程度
的保留。如下图所示:
作者还探索了服装一致性监督的效果,包括真实的服装分割图像 ,估计的平铺服装图像 以及真实的平铺服装图像。效果如下图:
结果显示,服装平铺网络有效地将试穿状态的服装转换为平铺状态。通过比较估计的和原始平铺服装,原始平铺服装具有更多的精细服装细节,这表明将服装平铺网络引入训练中,保留更真实服装细节。
结论
本文通过引入忠实的服装先验和服装一致的忠实监督,有效地缓解了因扩散随机性和隐式监督导致的服装细节不足的问题。采用这一方法后,生成的试穿图像更加逼真,衣物细节得到了更好的还原,为用户提供了更加真实、细致的虚拟试穿体验。
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。