今日arXiv最热NLP大模型论文:韩国团队提出ResearchAgent系统,模仿人类产出论文idea

夕小瑶科技说 原创
作者 | 谢年年
你是否还在苦于想发论文却没有idea?
在浩瀚无边的文献中苦苦寻找却又无从下手?
那些看似与你研究相关的文章,要么已经被人研究得透彻无比,要么与你的方向南辕北辙,让你倍感挫败。
不要慌,让AI来助你一臂之力,从文献调研到发现问题,从制定研究方法到设计实验,AI都能为你提供全程的支持与指导。
(别划走,真不是广告)
这是韩国科学院最近的一篇工作,利用LLM构建了一个ResearchAgent系统,模仿人类产出论文idea的步骤,一步一步引导LLMs生成包括问题识别、方法开发和实验设计等在内的完整研究思路,同时,引入与人类偏好一致的Reviewing Agents,对生成的研究思路进行迭代优化。该方法生成的Idea在清晰性,相关性,原创性,可行性,重要性五大评估标准上都有不错的表现。
论文标题
:
ResearchAgent: Iterative Research Idea Generation
over Scientific Literature with Large Language Models
论文链接
:
https://arxiv.org/pdf/2404.07738.pdf
方法
1. 由LLM驱动的idea生成
一篇科学论文的idea产生包括三个系统步骤:发现问题、制定方法和设计实验,这构成了一个质疑、创新和验证的循环。因此本文的目标包括了这三个完整的步骤。
本文主要使用现有的文献作为主要来源,提供问题来源。设为文献,为由问题、方法和实验设计组成的idea,如下所示:,然后,idea生成模型可以表示为:,进一步分解为三个子模块步骤:用于问题发现,用于方法开发,用于实验设计。
LLMs形式化:LLMs接受一系列tokens 作为输入,并生成一系列tokens作为输出,表示如下: ,其中是模型参数,是提示模板。
2. 知识增强的LLMs生成研究idea
本文通过将LLMs与任务特定模板相结合,将研究idea生成函数 实例化为LLM。形式上, 表示问题识别步骤,接着是 用于方法开发,以及 用于实验设计,这构成了完整的想法:。
2.1 文献综述
那么如何利用LLMs基于大量文献生成Idea呢? 由于其输入长度的限制和推理能力,不可能将所有现有文献 都纳入LLM输入中。因此,作者模仿人类研究人员的过程,通过查阅引用或被引用的其他论文来扩展对一篇论文的了解。
通过提供来自 的核心论文 来启动LLM的文献综述过程,然后有选择地纳入后续论文 。核心论文的选择及其相关引文的原则设计如下:
基于其引文计数(例如,在3个月内超过100次)选择核心论文,通常表示高影响力; 其相关论文(可能数量众多)根据其摘要与核心论文的相似性进一步缩小范围,确保更集中和相关的相关工作集。
尽管这种Idea生成方法简单直观,但它存在一个主要限制:它完全依赖于一组特定的论文(包括核心论文及其引文)。然而,科学知识并非仅局限于特定研究,而是在不同领域的众多文献中累积。一个Idea应当能够充分利用这种广泛、相互关联且相关的科学知识。
因此作者引入了实体增强知识之间的联系。
2.2 实体中心知识增强
为有效提取、存储和利用科学文献中的知识,本文将实体作为基本单元。通过实体链接方法,轻松地从论文中提取如“数据库”等术语,并统计其在知识存储库中的出现频率。例如,在分析不同学科时,发现“数据库”在医学中较常见,但在血液学中较少见。此时,知识存储机制便能发挥作用,基于共享实体捕捉领域间的相关性,并为血液学研究提供“数据库”等新颖跨学科见解。
知识库存储
作者将知识存储设计为一个二维矩阵 ,其中 表示所有唯一实体的总数, 以稀疏格式实现,以节省空间并提高计算效率。该知识库是通过提取文献中所有可用的科学文章的实体来构建的,它不仅计算单个论文中实体对之间的共现次数,而且还量化每个实体的出现次数。
为了进行实体提取,作者使用了一个现有的实体链接器EL来标记和规范化特定论文 的实体,形式化如下:,其中 表示出现在 中的实体的多重集(允许重复)。
在提取实体 后,将它们存储到知识存储 中,考虑所有可能的 对,表示如下:,其中 ,然后记录到 中。
实体增强idea生成
在给定知识存储 的基础上,下一步是利用一组相互关联的论文来增强基础研究idea的生成。表示如下:。
为了实现这一目标,将从知识存储中引入相关实体来丰富LLM的输入,从而扩展其可处理的上下文知识。这些实体虽然在当前论文组中未直接出现,但与其紧密相关,可通过分析中的实体共现信息来识别。
从相互关联的论文组中提取的实体如下:
。
然后,检索前 个相关外部实体的概率形式可以表示如下:
其中 ,且 。另外,为简单起见,通过应用贝叶斯规则并假设实体是独立的,检索操作(方程式 1)可以近似表示如下:
其中 和 可以由二维矩阵中的值得到,并适当地归一化。
接下来,以实体为中心的相关知识增强的生成实例表示为:
。下表展示了使用知识增强实例化LLM的模板(截取部分)。首先是基于论文信息与实体提炼出问题:
然后基于研究问题理由定制方法:
最后基于问题、方法设计实验:
3 利用人类偏好对齐的LLM Agent 迭代Idea
一次性完成论文的撰写在现实中是不可能的,这也与人类逐步改进的写作习惯相悖。人们通常会在多次审稿和反馈中不断优化初稿。为此,作者提出了一种迭代增强策略,利用LLM驱动的Reviewing Agents按照特定标准提供审稿和反馈,从而验证并改进生成的idea。
具体来说,类似于上面使用LLM和模板(T)实例化Research Agent的方法,这里也采用类似的方式来实例化Reviewing Agents,只不过这次使用的是不同的模板,如下表所示:
随后,这些Reviewing Agents会根据它们各自设定的五个特定标准:Clarity、Relevance、Originality、Feasibility、Significance,对生成的idea(包括问题、方法和实验设计)分别进行独立评估,如下图所示。基于Reviewing Agents提供的审查和反馈,Research Agent将进一步更新和完善已生成的idea,以实现更高质量的研究输出。
为了获取与人类一致的评估标准,作者收集了10对研究思路及其得分,每个标准均基于至少3篇人类研究人员的论文标注。随后,这些标注被用作样本,提示LLM归纳出反映人类偏好的详细描述作为评估标准。最终,这些标准将被应用于Reviewing Agents,并嵌入评估提示模板中,以提升评估过程与人类判断的契合度。
实验
1.数据来源
科学文献,通过Semantic Scholar Academic Graph API获取,优先选择那些引用次数超过20次的高影响力论文作为核心文献。从中随机抽取了300篇论文作为核心样本。这意味着将为每个模型生成并评估300个idea。统计数据显示,每篇核心论文平均引用87篇参考文献,而每篇论文的摘要中平均包含2.17个实体。下图展示了这些论文的学科分布,显示了跨学科的广泛覆盖范围。
2. 基线模型
在这项工作中,鉴于Idea生成是一项新任务,并未发现现成的基线模型可供直接比较。因此,作者设计了几个消融变体,并将其与完整的ResearchAgent模型进行对比。以下是这些变体的简要描述:
- Naive ResearchAgent:这个变体仅使用核心论文作为输入来生成Idea。它忽略了其他可能的信息来源,如相关参考文献或实体。
- ResearchAgent w/o Entity Retrieval:此变体考虑了核心论文及其相关参考文献,但没有包含从论文中提取的实体信息。这意味着LLM在生成Idea时不会利用这些实体作为上下文或指导。
- ResearchAgent(完整模型):结合了核心论文、相关参考文献以及从论文中提取的实体信息。
3. 评估设置
研究idea生成是一个新任务,没有 ground-truth来衡量生成的质量。此外,构建新的核心论文和idea对也不是最佳选择,因为每篇核心论文可能存在大量有效的Idea,而这个过程需要人类研究者投入大量时间、精力和专业知识。因此,作者采取基于模型的自动评估以及人类评估结合的方法,要求评估模型根据五大标准评价生成的idea,或者在不同模型生成的两个idea之间进行成对比较。
实验结果分析
主要结果
下图提供了关于人类和基于模型的评估得分的主要结果。这些结果表明,完整Research Agent在所有指标上都大幅优于所有基线。
带有实体增强的Research Agent在创造力相关指标上实现了显著增长,(例如问题的独创性和方法的创新性)。这是因为实体可能引入新颖概念和观点,而这些在仅依赖论文组(核心论文及其参考文献)生成想法时可能难以察觉。
此外,作者报告了任何两个模型之间的成对比较结果报告,如下图所示,完整的ResearchAgent在其基线上显示出最高的胜率
消融实验
标注者一致性的分析
为了确保人类标注的质量和可靠性,评估标注者的一致性,作者随机抽取了20%生成的idea,并由两名人类评估者进行评分。采用了两种评估方法:一是将每位标注者的分数进行排名,并计算两个标注者排名分数之间的Spearman相关系数,以衡量评分的一致性;二是作成对比较,计算了Cohen's kappa系数以评估他们在判断上的相似度。
如下表所示,测量结果显示标注者之间的一致性非常高,这验证了我们对生成的研究想法质量评估的可靠性。
另外,作者测量了基于人类和基于模型的评估之间的一致性,以确保基于模型的评估的可靠性。同样显示在下表中,进一步确认人类和模型之间的一致性很高,表明基于模型的评估是判断研究想法生成的一个合理替代方法。
ReviewingAgents中迭代步骤是否有用?
作者报告了idea迭代步骤对效果的影响。如下图所示,随着步骤的增加,生成的idea的质量有所改善。然而,在三次迭代后,性能变得饱和。
知识来源消融
本文提出的完整ResearchAgent增强了两种不同的知识来源,即相关参考文献和实体。为了查看每个知识来源的个体贡献,作者通过排除其中一个知识来源或将其替换为随机元素来进行消融研究。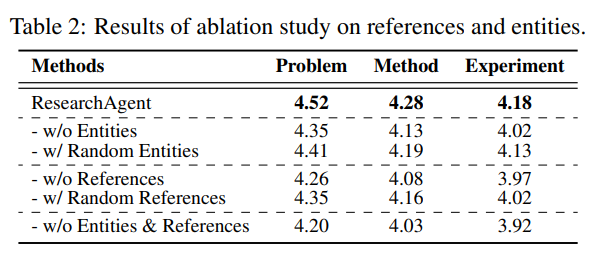
如上表所示,每个知识来源都有助于性能改进。此外,没有相关参考文献时性能显著下降,这证实了它们在生成高质量研究想法中的重要性。
分析评估中的人类对齐
为了将基于模型的评估结果与实际人类偏好对齐,作者使用GPT-4基于人类评估结果生成了评估标准,并将其用作基于模型的评估的标准。
上图对比了人类评估与基于模型的评估(有无人类对齐)的分数分布。在没有进行人类对齐时,基于模型的评估分数分布呈现出倾斜现象,与人类判断的分数分布存在显著差异。然而,当评分标准对齐后,校准后的分数分布明显更接近人类的分布,显示出更高的准确性和一致性。这一结果证明了人类对齐在提升模型评估质量方面的重要性。
引文数量的相关性
作者深入探讨了高影响力论文作为核心论文时,是否有助于生成高质量的Idea。为验证这一点,依据引文数量将论文划分为三组,并基于模型评估在下图中展示了各组的平均分数。
结果显示,高影响力论文通常能产生更高质量的思路。
另外本文基于模型评估标准主要聚焦于计算机科学论文。为检验这些标准在不同领域的适用性,还比较了计算机科学论文与整体论文的得分相关性。结论是:无论哪个领域,得分均随引文数量增加而上升,这可能表明人类偏好驱动的评估标准具有泛化潜力。
使用不同的LLMs
除了利用最强大的GPT-4模型,作者将ResearchAgent实例化为GPT-3.5。
通过上表的基于模型评估结果,可以观察到,当使用性能稍逊的GPT-3.5时,ResearchAgent的性能出现了显著下降。
同时,值得注意的是,在没有知识增强的情况下,普通的ResearchAgent与完整ResearchAgent之间的性能差异变得微乎其微。
这些结果表明,GPT-3.5可能难以捕捉跨不同科学论文的复杂概念及其关系。这也是作者选择GPT-4作为ResearchAgent的原因。
结论
本文提出的ResearchAgent系统,模仿人类产出论文idea的步骤,一步一步增强LLMs生成包括问题识别、方法开发和实验设计等在内的完整研究思路,同时,引入多个与人类偏好一致的LLM驱动的ReviewingAgents,迭代优化生成的研究思路。
我们期待ResearchAgent能成为科研人员的得力助手,共同发掘激动人心的研究idea,加速科学研究过程。
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。