强化学习第十三篇:使用深度学习解决迷宫问题,完整步骤和代码
你好,我是郭震
前面强化学习推送到第十二篇,迷宫问题已使用Q-learning解决过,今天使用另一种方法:深度Q网络,简称DQN网络解决。
什么是DQN?
深度Q网络(Deep Q-Network, DQN)是一种结合了深度学习和强化学习的算法,旨在解决具有高维观测空间的决策问题。它是由
DeepMind在2015年提出的,用于成功地在多个Atari 2600游戏上训练智能体,实现了超越人类玩家的性能。DQN成为了深度强化学习领域的一个重要里程碑,开启了使用深度学习方法解决复杂强化学习问题的新纪元。DQN在许多领域展现了其强大的能力,包括但不限于游戏玩法、机器人控制和自动驾驶。DQN及其变种(如Double DQN、Dueling DQN等)为后续深度强化学习研究和应用提供了坚实的基础,推动了该领域的快速发展。DQN 原理?
DQN的核心思想是使用一个深度神经网络来近似Q函数(动作价值函数),这个Q函数预测在给定状态下采取每个可能动作的预期回报(累积奖励)。传统的Q学习算法依赖于一个Q表来存储和更新每个状态-动作对的Q值,但这种方法在面对高维状态空间时变得不切实际。DQN通过使用深度神经网络来克服这个限制,使得可以处理复杂、高维的输入状态,如图像。关键创新
DQN引入了几个关键的创新来增强学习的稳定性和效率:
经验回放(Experience Replay):智能体的经验(状态、动作、奖励和下一个状态)在每个时间步被存储在一个回放缓冲区中。训练网络时,会从这个缓冲区中随机抽取一小批经验进行学习,这有助于打破经验之间的相关性,并使得每个经验可以被多次重复使用,提高数据效率。固定Q目标(Fixed Q-targets):为了减少训练过程中的目标Q值与预测Q值之间的相关性,DQN使用了两个网络:一个用于当前步骤的Q值预测,另一个用于计算目标Q值。目标网络的权重定期(而非每步)从预测网络复制过来,从而增加学习的稳定性。
DQN求解迷宫问题
要使用深度Q网络(DQN)解决迷宫问题,我们首先需要建立一个环境类,该类能够处理与智能体的交互:提供状态、接受动作、返回新状态和奖励等。接着,我们将使用DQN来学习在该环境中达到目标的策略。
使用模块:
import numpy as np
import torch.nn as nn
import torch
from torch.optim import Adam
from collections import deque
import random
import matplotlib.pyplot as plt
步骤一:定义迷宫环境类
class MazeEnv:
def __init__(self):
self.exit_coord = (3, 3)
self.row_n, self.col_n = 4, 4
self.walls = {(0, 3), (1, 0), (1, 2), (2, 2), (3, 0)}
self.state = (0, 0) # 初始状态
self.actions = [0, 1, 2, 3] # 上、下、左、右
self.reset()
def reset(self):
self.state = (0, 0) # 重置智能体的位置到起点
return self.state
def step(self, action):
row, col = self.state
if action == 0: # 上
next_state = (max(row - 1, 0), col)
elif action == 1: # 下
next_state = (min(row + 1, self.row_n - 1), col)
elif action == 2: # 左
next_state = (row, max(col - 1, 0))
elif action == 3: # 右
next_state = (row, min(col + 1, self.col_n - 1))
else:
raise ValueError("Invalid action")
reward = -1 # 默认奖励
done = False
if next_state in self.walls:
reward = -10
elif next_state == self.exit_coord:
reward = 10
done = True
self.state = next_state if next_state not in self.walls else self.state
return self.state, reward, done
def get_state_size(self):
return self.row_n * self.col_n
def get_action_size(self):
return len(self.actions)
步骤二:定义DQN神经网络模型
# DQN模型
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
output = self.fc3(x)
return output
步骤三:定义经验回收
# 经验回放
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))
return np.array(state), action, reward, np.array(next_state), done
def __len__(self):
return len(self.buffer)
步骤四:定义更新DQN函数
def update_model(dqn_model, target_dqn_model, replay_buffer, optimizer, batch_size, gamma):
# 从经验回放缓冲区中随机采样一批经验
state, action, reward, next_state, done = replay_buffer.sample(batch_size)
# 转换列表为Tensor
state = torch.FloatTensor(state)
action = torch.LongTensor(action)
reward = torch.FloatTensor(reward)
next_state = torch.FloatTensor(next_state)
done = torch.FloatTensor(done)
# 计算当前状态下,采取实际动作的Q值
current_q_values = dqn_model(state).gather(1, action.unsqueeze(1)).squeeze(1)
# 使用目标DQN模型计算下一状态的最大Q值
next_q_values = target_dqn_model(next_state).max(1)[0]
# 计算期望Q值
expected_q_values = reward + gamma * next_q_values * (1 - done)
# 计算损失
loss = torch.nn.functional.mse_loss(current_q_values, expected_q_values.detach())
# 优化器梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新模型权重
optimizer.step()
步骤五:训练DQN
# 训练DQN
def train_dqn(epochs=300):
global epsilon
for epoch in range(epochs):
state = env.reset()
state = np.eye(env.row_n * env.col_n)[state[0] * env.col_n + state[1]]
total_reward = 0
done = False
while not done:
if random.random() < epsilon:
action = random.choice(env.actions)
else:
q_values = dqn_model(torch.FloatTensor(state).unsqueeze(0))
action = torch.argmax(q_values).item()
next_state, reward, done = env.step(action)
next_state = np.eye(env.row_n * env.col_n)[next_state[0] * env.col_n + next_state[1]]
replay_buffer.push(state, action, reward, next_state, done)
state = next_state
total_reward += reward
if len(replay_buffer) > batch_size:
update_model(dqn_model, target_dqn_model, replay_buffer, optimizer, batch_size, gamma)
epsilon = max(epsilon_min, epsilon_decay * epsilon)
print(f'Epoch: {epoch}, Total Reward: {total_reward}')
reward_list.append(total_reward)
if epoch % 10 == 0:
target_dqn_model.load_state_dict(dqn_model.state_dict())
步骤六:结果分析
if __name__ == "__main__":
# 初始化环境
env = MazeEnv()
# 初始化DQN
state_size = env.get_state_size()
action_size = env.get_action_size()
dqn_model = DQN(input_dim=state_size, output_dim=action_size)
target_dqn_model = DQN(input_dim=state_size, output_dim=action_size)
target_dqn_model.load_state_dict(dqn_model.state_dict())
optimizer = Adam(dqn_model.parameters(), lr=1e-4)
replay_buffer = ReplayBuffer(10000)
batch_size = 64
gamma = 0.99
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
reward_list = []
train_dqn()
x = range(len(reward_list))
plt.plot(x, reward_list, label='Line', color='blue')
plt.xlabel("step")
plt.ylabel("reward")
plt.title("DQN to solve the 4*4 maze problem")
plt.show()以上代码可运行,绘制step vs reward 折线图,看到奖励逐渐变大且最终收敛,大概在200时步。
使用得到的模型,预测最优迷宫行走路径:
def simulate_optimal_path(model, env):
state = env.reset()
optimal_path = [state] # 记录最优路径的状态
done = False
while not done:
state = np.eye(env.row_n * env.col_n)[state[0] * env.col_n + state[1]]
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
action = model(state_tensor).max(1)[1].view(1, 1)
next_state, _, done = env.step(action.item())
optimal_path.append(next_state)
state = next_state
return optimal_path
调用:
optimal_path = simulate_optimal_path(dqn_model, env)
print(optimal_path)
打印出来的最优行走路线:
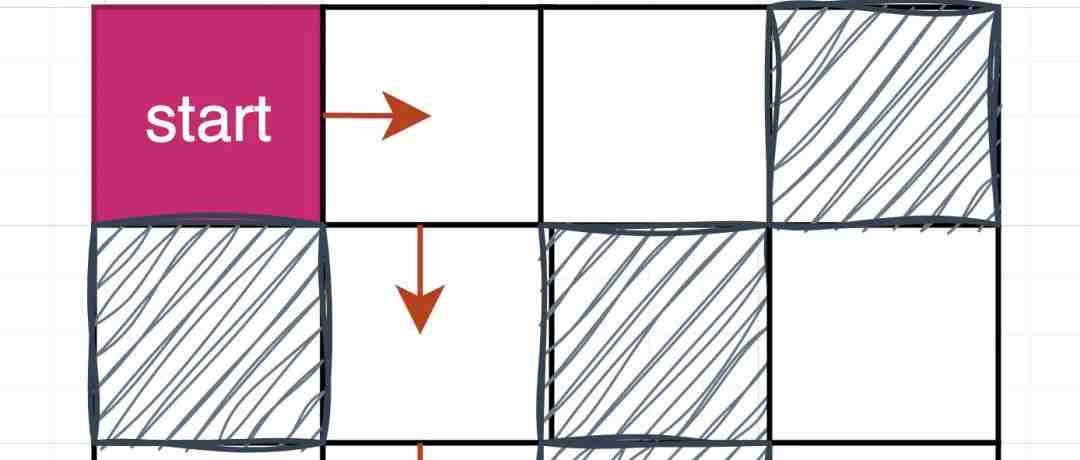
[(0, 0), (0, 1), (1, 1), (2, 1), (3, 1), (3, 2), (3, 3)]
也就是下图中的行走路线:
以上,使用DQN求解迷宫问题的完整步骤和代码。
下期再见!
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。