Jupyter notebook 配置虚拟环境,很多人都遇到这个问题,完整解决步骤!
你好,我是郭震
Jupyter notebook 最常用的数据分析工具,虚拟环境是包隔离沙箱,两个是多Python项目管理必备工具。
一个经常出现的问题,可能困扰过或正在困扰很多朋友。
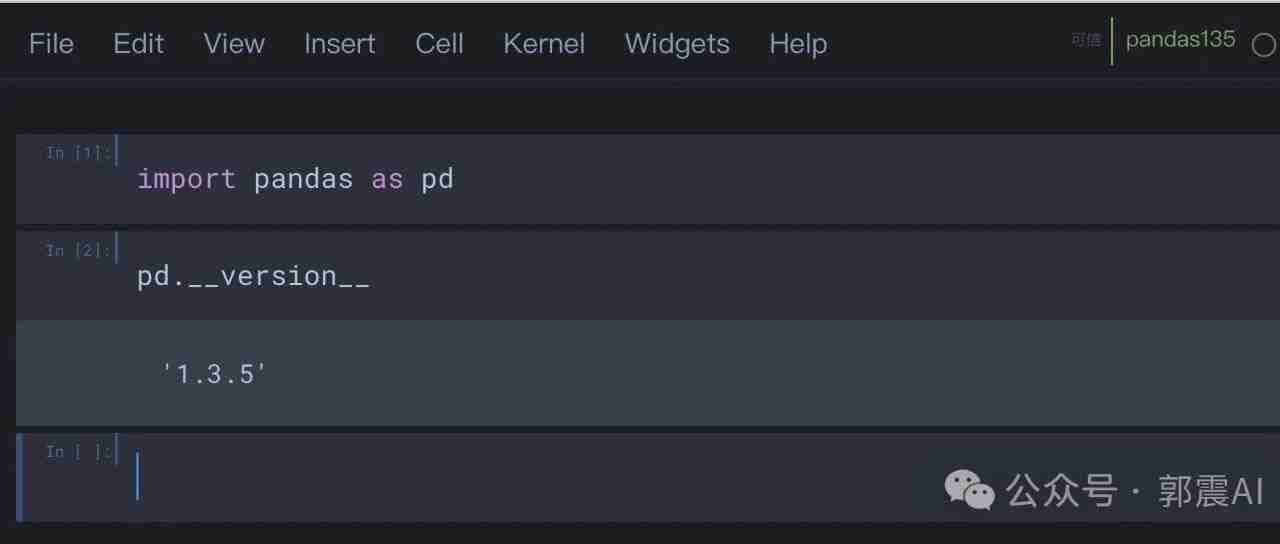
“在 data-science 虚拟环境中,安装 pandas 包是 1.3.5 版本,但是 jupyter notebook 打开,显示却是 1.3.4 版本,怎么都解决不了。
问题原因:
data-science 环境若未安装jupyter notebook 直接走 base 环境,所以加载的依然还是 base 里的 pandas
详细解决步骤:
- 切换到
data-science环境,使用命令:conda activate data-science - 安装
jupyter notebook,使用命令:pip install notebook - 配置一个
jupyter notebokpython -m ipykernel install --user --name data-science(调整为你的虚拟环境名称) --display-name "pandas135"(可以另起一个自己的名字) - 最后输入:
jupyter notebook
重点解释步骤3
命令
python -m ipykernel install --user --name your_env_name --display-name "Display Name" 的作用是将指定的Python虚拟环境添加到Jupyter Notebook中,作为一个可选择的内核。这样做之后,你就能在Jupyter Notebook中启动并使用这个虚拟环境,运行其中安装的库和模块。具体来说,这个命令的各个部分有以下作用:python -m ipykernel install:使用Python执行ipykernel模块的安装命令,ipykernel是IPython的内核,Jupyter Notebook依赖它来运行Python代码。--user:这个选项指定安装内核仅对当前用户可用,而不是系统级别的安装。这有助于避免对系统全局设置的更改,尤其是在多用户系统上。--name your_env_name:这里your_env_name是你为虚拟环境指定的名称。这个选项指定了将要注册到Jupyter中的内核的名称,这个名称是在系统级别识别该虚拟环境的唯一标识。--display-name "Display Name":"Display Name"是在Jupyter Notebook界面中显示的内核名称,你可以自定义这个名称,使其更易于识别。
看到
New 下,会多一个 pandas135,选择它:看到已经加载到 1.3.5 版本的 Pandas:
以上步骤。阅读更多,https://zglg.work
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。