FuseLLM:大语言模型的知识融合!
深度学习自然语言处理 原创
作者:wkk
作者:wkk
论文:KNOWLEDGE FUSION OF LARGE LANGUAGE MODELS地址:https://arxiv.org/pdf/2401.10491.pdfgit: https://github.com/fanqiwan/FuseLLM
小伙伴们好久没见,今天为大家介绍中山大学联合腾讯人工智能实验室的最新研究论文,关于整合LLM知识能力的框架。
引言
当进行LLM工作时,如果从头开始训练LLM可以生成具有不同功能和优势的模型,但这会带来巨大的成本,并可能导致冗余功能。或者使用一种具有成本效益和说服力的方法是将现有的预先训练的LLM合并到一个更有效的模型中。然而,由于已有LLM的架构各不相同,直接混合它们的权重是不切实际的。
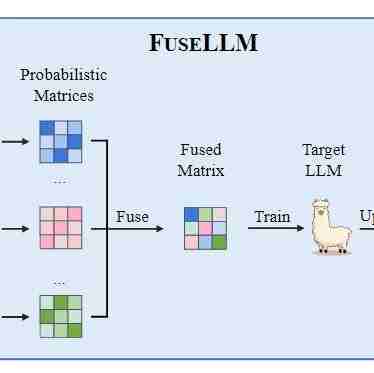
在本文中,引入了LLM的知识融合概念,旨在将现有LLM的能力结合起来,并将其转移到单个LLM中。通过利用源LLM的生成分布,将其集体知识和独特优势外部化,从而有可能将目标模型的能力提升到任何单个源LLM之外。
动机
随着GPT和LlaMA系列等大型语言模型在各种自然语言处理任务中的不断成功,创建自己的LLM已成为企业的战略当务之急。然而,LLM开发的相关成本是天文数字。除了需要大量的训练数据、先进的技术、大量的计算资源和熟练的劳动力外,开发过程还对能源消耗和环境施加了巨大压力。
相关工作
Model Fusing: 模型融合的常见方法通常采用加权平均或多数投票来融合各种模型的预测。最近,有研究人员提出了一种集成框架,旨在利用多个开源LLM的不同优势。该框架首先采用成对比较方法来检测候选输出之间的细微区别。然后,它将排名靠前的候选人结合起来,产生更高的产出,利用它们的优势,同时减轻它们的弱点。虽然模型集成需要并行部署多个模型,但权重合并通常仅限于具有相同架构的模型。相反,本文提出的方法通过将多个LLM的知识和能力明确地转移到目标LLM,支持将多个具有不同架构的LLM融合。 Knowledge Distillation:知识蒸馏最初被提出用于模型压缩,包括在一个或多个教师模型的指导下训练学生模型。在NLP中已有较为广泛的应用。本文的方法与传统的知识蒸馏有显著的区别。首先,在传统的知识蒸馏中,学生模型通常被限制为比教师更小的尺寸。然而,在本文的场景中,目标模型的大小没有限制。其次,传统的知识蒸馏通常会导致学生模型在蒸馏后落后于教师的表现。相比之下,本文预计在融合之后,目标模型将超过任何源模型的性能。
方法
模型架构
实验
实验设置
数据集:MiniPile包含22个域中的大约100万个文档和1.8亿个token,占Llama-2的2万亿个训练标记中的不到0.1%。 融合函数:对于融合函数,本文使用最小化交叉熵。同时使用其他的替代融合函数进行消融实验。 训练细节:使用128的批量大小和配备8个NVIDIA A100 GPU的单个节点上的最大长度为2048来训练Llama-2 7B的目标LLM,每个节点有40GB的内存。训练框架是基于Huggingface Transformers实现的,并使用FlashAttention加速。本文的模型使用AdamW优化器进行优化,β1=0.9,β2=0.95,梯度裁剪设置为1.0,权重衰减为0.1。采用余弦学习率,最大学习率为1e-5,预热率为0.008。 评估:本文在三个基准上评估FuseLLM,这三个基准代表了LLM的不同核心功能,即跨越推理、常识和代码生成。
实验结果
上表展示了与BBH上的基线方法相比,FuseLLM的总体结果。可以观察到:
三个源LLM在27个 BBH 任务中表现出不同的性能,Llama-2通常优于其他任务。 在使用紧凑多样的语料库进行持续训练后,与Llama-2相比,Llama-2 CLM显示出1.86%的相对改进,尽管这种改进在任务之间相对温和且不一致。 平均而言,FuseLLM在所有27个任务中比原始Llama-2的平均相对性能增益为5.16%。在特定任务中,FuseLLM实现的增强是显着的。 在像Dick Languages这样的任务中,简单的连续预训练会导致性能下降,FuseLLM利用单个源LLM的组合优势来恢复性能改进。 FuseLLM偶尔会在几何形状和单词排序等任务上表现出性能下降,这可以归因于两个原因。首先,除了Llama-2之外,其他源LLM在这些任务上表现不佳,影响了融合结果。其次,连续训练数据集和下游任务之间的相关性导致性能下降。
上表展示了FuseLLM和Common Sense (CS)基准上基线方法的零样本性能。结果表明:
FuseLLM在所有五个任务中始终优于基线,与Llama-2相比,相对性能提1.25%。相比之下,Llama-2 CLM 表现出边际改进,与Llama-2相比,相对增强只有0.16%。 在具有挑战性的ARC-challenge(2.40%)和OpenBookQA(2.71%)任务中观察到Llama-2到FuseLLM的实质性改进,突出了FuseLLM在利用集体知识来解决复杂问题方面的有效性。
对于代码生成评估,FuseLLM在 MultiPL-E(ME)基准上的零样本性能如上表所示。观察到:
FuseLLM在10个任务中的9个上优于Llama-2,在特定编程语言(如R)的分数显着提高,从4.97增加到5.84。 与Llama-2相比,OpenLLaMA和MPT在代码生成任务中都表现出显着的性能,FuseLLM的融合结果平均性能增益为6.36%,远高于Llama-2 CLM中观察到的1.37%的改进。
融合概率分布
本文研究了从多个LLM获得的融合概率分布的有效性,并跟踪了训练过程中性能改进的趋势。
上图显示了Llama-2 CLM和FuseLLM在BBH上不同规模的训练数据下的few-shot CoT性能的比较。结果表明:
与Llama-2 CLM相比,FuseLLM将精确匹配精度提高了2.5%,并在0.52亿个token内实现了Llama-2 CLM的最佳性能。 与Llama-2 CLM所需的15.7亿token相比,这意味着token需求减少了3.9倍。
这些结果表明,从LLM导出的概率分布包含比原始文本序列更容易学习的知识,加速了优化过程。
实现过程分析
本文还对FuseLLM的关键元素进行分析包括:源LLM的数量、token对齐标准以及融合函数的选择。
源LLM的数量:上表给出了融合不同数量LLM的结果。随着模型数量从1增加到3,FuseLLM的性能有了明显的改进。在BBH中观察到持续的性能改进。而在CS或ME中,当融合两个模型时,优势更加突出。这一现象可能归因于三个模型在BBH中的各种任务上的性能差异很大,而CS或ME在任务上的表现差异相对较小。
token对齐标准:在LLM的融合过程中,确保来自多个模型的令牌和词汇表的正确对齐至关重要。上表对两种对齐标准进行了比较。很明显,所提出的基于最小编辑距离的MinED方法始终优于EM方法。后者依赖于精确匹配。导致的性能增强是由于MinED能够放松EM的约束,因为在同一序列中由不同的标记器分离的标记通常表现出微小的差异。
融合函数:最小交叉熵的分布矩阵和基于交叉熵的分配矩阵的加权平均。两种融合函数的比较如上表所示。在所有基准测试中,带有MinCE的FuseLLM始终优于AvgCE。这可归因于AvgCE中使用的直接加权求和所引入的失真,这可能会削弱单个LLM的独特优势。
知识融合vs.知识蒸馏
知识蒸馏技术也可以用来增强LLM的能力,但FuseLLM由于两个不同的方面而脱颖而出,本文从Llama-2 13B 中提取概率分布,并应用传统的知识蒸馏方法将其能力转移到Llama-2 7B中。如上表所示:
蒸馏模型在所有基准测试中都优于原始的Llama2 7B,证明了知识蒸馏的有效性。 与FuseLLM相比,Llama-2 KD实现的改进相对适中。这表明FuseLLM 通过通过连续训练集成三个具有不同架构的7B模型来实现的卓越性能超过了简单地从单个13B模型中提取知识的好处。
知识融合vs.集成/合并
本文进行了实验,模拟多个LLM来自同一个基本模型,但在不同的语料库上进行训练的场景。
上表结果中观察到,在使用10亿个token进行训练后,原始LLM的能力会转移到每个特定领域的LLM,导致其他领域的性能下降。虽然所有的融合技术都可以集成不同模型的优势,但FuseLLM在三个领域中始终实现最低的困惑程度。这突出了它比集合和权重合并方法更有效地利用集体知识的潜力。
总结
在这项研究中,探索了LLM的知识融合领域,以创建一个统一的模型,将多个结构不同的LLM的能力和独特优势相结合。并介绍了一种新的方法:FuseLLM,它利用这些源LLM的生成分布来外部化它们的知识,并将它们用于目标LLM的持续训练。一系列实验证明了FuseLLM相对于单个源LLM的优越性,并建立了基线。LLM融合领域成为一种更有前景的探索途径,特别是考虑到了LLM的不同结构和大量模型大小。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。