图解大模型计算加速系列:Flash Attention V1,从硬件到计算逻辑
大家好哇,好久没有更新了,今天想来讲讲Flash Attention(V1)。
不知道你有没有和我一样的感受,第一次读Flash Attention的论文时,感觉头懵懵的:它不仅涉及了硬件和cuda的知识,还涉及到很多计算逻辑上的trick。我的痛点是不能在头脑中具象化整个流程,就更不要提对细节的推导了。
所以这篇文章我读了很久,也写了很久(一个月),最终决定按照如下方式对Flash Attention进行介绍:
- 本文一到三部分,介绍相关硬件知识及Flash Attention诞生背景。
- 本文四到五部分,通过图解形式介绍forward/backward中的分块计算过程。所有的符号、公式都会给出详细的说明和推导过程。我在阅读中发现论文的一些推导不太符合直觉(or写得可能不太对),所以这里我在遵从论文符号表达的基础上,部分内容按自己的理解重新顺了一遍。
- 本文第六到第八部分,量化介绍Flash attention在性能上的改进,包括计算量、显存和IO复杂度。
【本文较长(1.5w字),符号较多,建议PC端阅读~写作与绘图不易,如果大家觉得有帮助,可以点个小小的赞和在看~~】
一、Flash attention在做一件什么事
我们知道,对于Transformer类的模型,假设其输入序列长度为,那么其计算复杂度和消耗的存储空间都为。也就是说,随着输入序列的变长,将给计算和存储带来极大的压力。
因此,我们迫切需要一种办法,能解决Transformer模型的复杂度问题。如果能降到,那是最好的,即使做不到,逼近那也是可以的。所以,Flash Attention就作为一种行之有效的解决方案出现了。
Flash Attention在做的事情,其实都包含在它的命名中了(Fast and Memory Efficient Exact Attention with IO-Awareness),我们逐一来看:
(1)Fast(with IO-Awareness),计算快。在Flash Attention之前,也出现过一些加速Transformer计算的方法,这些方法的着眼点是“减少计算量FLOPs”,例如用一个稀疏attention做近似计算。但是Flash attention就不一样了,它并没有减少总的计算量,因为它发现:计算慢的卡点不在运算能力,而是在读写速度上。所以它通过降低对显存(HBM)的访问次数来加快整体运算速度,这种方法又被称为IO-Awareness。在后文中,我们会详细来看Flash Attention是如何通过分块计算(tiling)和核函数融合(kernel fusion)来降低对显存的访问。
(2)Memory Efficicent,节省显存。在标准attention场景中,forward时我们会计算并保存N*N大小的注意力矩阵;在backward时我们又会读取它做梯度计算,这就给硬件造成了的存储压力。在Flash Attention中,则巧妙避开了这点,使得存储压力降至。在后文中我们会详细看这个trick。
(3)Exact Attention,精准注意力。在(1)中我们说过,之前的办法会采用类似于“稀疏attention”的方法做近似。这样虽然能减少计算量,但算出来的结果并不完全等同于标准attention下的结果。但是Flash Attention却做到了完全等同于标准attention的实现方式,这也是后文我们讲述的要点。
二、计算限制与内存限制
在第一部分中我们提过,Flash Attention一个很重要的改进点是:由于它发现Transformer的计算瓶颈不在运算能力,而在读写速度上。因此它着手降低了对显存数据的访问次数,这才把整体计算效率提了上来。所以现在我们要问了:它是怎么知道卡点在读写速度上的?
为了解答这个问题,我们先来看几个重要概念:
:硬件算力上限。指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。 :硬件带宽上限。指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。 :某个算法所需的总运算量,单位是FLOPs。下标表示total。 :某个算法所需的总数据读取存储量,单位是Byte。下标表示total。
这里再强调一下对FLOPS和FLOPs的解释:
FLOPS:等同于FLOP/s,表示Floating Point Operations Per Second,即每秒执行的浮点数操作次数,用于衡量硬件计算性能。 FLOPs:表示Floating Point Operations,表示某个算法的总计算量(即总浮点运算次数),用于衡量一个算法的复杂度。
我们知道,在执行运算的过程中,时间不仅花在计算本身上,也花在数据读取存储上,所以现在我们定义:
- :对某个算法而言,计算所耗费的时间,单位为s,下标cal表示calculate。其满足。
- :对某个算法而言,读取存储数据所耗费的时间,单位为s。其满足
我们知道,数据在读取的同时,可以计算;在计算的同时也可以读取,所以我们有:
:对某个算法而言,完成整个计算所耗费的总时间,单位为s。其满足
也就是说,最终一个算法运行的总时间,取决于计算时间和数据读取时间中的最大值。
2.1 计算限制
当时,算法运行的瓶颈在计算上,我们称这种情况为计算限制(math-bound)。此时我们有:,即:
2.2 内存限制
当时,算法运行的瓶颈在数据读取上,我们称这种情况为内存限制(memory-bound)。此时我们有,即:
我们称为算法的计算强度(Operational Intensity)
2.3 Attention计算中的计算与内存限制
本节内容参考自:https://zhuanlan.zhihu.com/p/639228219
有了2.1和2.2的前置知识,现在我们可以来分析影响Transformer计算效率的因素到底是什么了。我们把目光聚焦到attention矩阵的计算上,其计算复杂度为,是Transformer计算耗时的大头。
假设我们现在采用的硬件为A100-40GB SXM,同时采用混合精度训练(可理解为训练过程中的计算和存储都是fp16形式的,一个元素占用2byte)
假定我们现在有矩阵,其中为序列长度,为embedding dim。现在我们要计算,则有(对FLOPs要怎么算不了解的朋友,可以跳到6.1节进行阅读):
不同取值下的受限类型如下:
根据这个表格,我们可以来做下总结:
- 计算限制(math-bound):大矩阵乘法(N和d都非常大)、通道数很大的卷积运算。相对而言,读得快,算得慢。
- 内存限制(memory-bound):逐点运算操作。例如:激活函数、dropout、mask、softmax、BN和LN。相对而言,算得快,读得慢。
所以,我们第一部分中所说,“Transformer计算受限于数据读取”也不是绝对的,要综合硬件本身和模型大小来综合判断。但从表中的结果我们可知,memory-bound的情况还是普遍存在的,所以Flash attention的改进思想在很多场景下依然适用。
在Flash attention中,计算注意力矩阵时的softmax计算就受到了内存限制,这也是flash attention的重点优化对象,我们会在下文来详细看这一点。
2.4 roof-line模型
其实到2.3为止,我们对计算限制和内存限制的概念已经知道得很清楚了。在这一节中,我们更系统来做一个总结。
一个算法运行的效率是离不开硬件本身的。我们往往想知道:对于一个运算量为,数据读取存储量为的算法,它在算力上限为,带宽上限为的硬件上,能达到的最大性能(Attanable Performance)是多少?
这里最大性能指的是当前算法实际运行在硬件上时,每秒最多能达到的计算次数,单位是
FLOP/s。Roof-line模型就是为了解答这一问题而提出的,它能直观帮我们看到算法在硬件上能跑得多快,模型见下图。
如图,横坐标表示计算强度,满足;纵坐标表示算法运行在硬件上的性能。算法的运行性能不会超过硬件本身的计算上限,所以的最大值取到。根据我们之前的分析,当时,存在计算限制;当时,存在内存限制。
三、GPU上的存储与计算
由于Flash attention的优化核心是减少数据读取的时间,而数据读取这块又离不开数据在硬件上的流转过程,所以这里我们简单介绍一些GPU上的存储与计算内容,作为Flash attention的背景知识。
3.1 GPU的存储分类
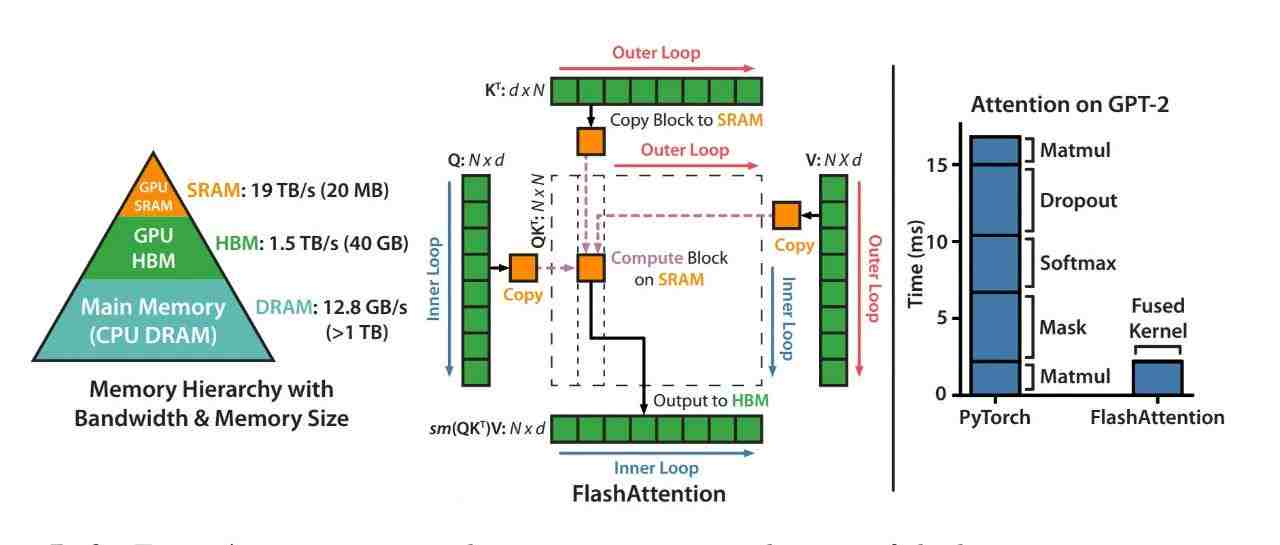
上图是Flash attention论文所绘制的硬件不同的存储类型、存储大小和带宽。一般来说,GPU上的存储分类,可以按照是否在芯片上分为片上内存(on chip)和片下内存(off chip)。
- 片上内存:主要用于缓存(cache)及少量特殊存储单元(例如texture),其特点是“存储空间小,但带宽大”。对应到上图中,SRAM就属于片上内存,它的存储空间只有20MB,但是带宽可以达到19TB/s。
- 片下内存:主要用于全局存储(global memory),即我们常说的显存,其特点是“存储空间大,但带宽小”,对应到上图中,HBM就属于片下内存(也就是显存),它的存储空间有40GB(A100 40GB),但带宽相比于SRAM就小得多,只有1.5TB/s。
当硬件开始计算时,会先从显存(HBM)中把数据加载到片上(SRAM),在片上进行计算,然后将计算结果再写回显存中。那么这个“片上”具体长什么样,它又是怎么计算数据的呢?
3.2 GPU是如何做计算的
如图,负责GPU计算的一个核心组件叫SM(Streaming Multiprocessors,流式多处理器),可以将其理解成GPU的计算单元,一个SM又可以由若干个SMP(SM Partition)组成,例如图中就由4个SMP组成。SM就好比CPU中的一个核,但不同的是一个CPU核一般运行一个线程,但是一个SM却可以运行多个轻量级线程(由Warp Scheduler控制,一个Warp Scheduler会抓一束线程(32个)放入cuda core(图中绿色小块)中进行计算)。
我们将上图所示的结构再做一次简化:
- DRAM:可以理解成是全局存储,也即可以当成是我们的显存
- L1缓存:每个SM都有自己的L1缓存,用于存储SM内的数据,被SM内所有的cuda cores共享。SM间不能互相访问彼此的L1。Flash attention中SRAM是on-chip的,对应到这里就是L1缓存。
- L2缓存:所有SM共享L2缓存。L1/L2缓存的带宽都要比显存的带宽要大,也就是读写速度更快,但是它们的存储量更小。
现在我们再理一遍GPU的计算流程:将数据从显存(HBM)加载至on-chip的SRAM中,然后由SM读取并进行计算。计算结果再通过SRAM返回给显存。
我们知道显存的带宽相比SRAM要小的多,读一次数据是很费时的,但是SRAM存储又太小,装不下太多数据。所以我们就以SRAM的存储为上限,尽量保证每次加载数据都把SRAM给打满,节省数据读取时间。
3.3 kernel融合
前面说过,由于从显存读一次数据是耗时的,因此在SRAM存储容许的情况下,能合并的计算我们尽量合并在一起,避免重复从显存读取数据。
举例来说,我现在要做计算A和计算B。在老方法里,我做完A后得到一个中间结果,写回显存,然后再从显存中把这个结果加载到SRAM,做计算B。但是现在我发现SRAM完全有能力存下我的中间结果,那我就可以把A和B放在一起做了,这样就能节省很多读取时间,我们管这样的操作叫kernel融合。
由于篇幅限制,我们无法详细解释kernel这个概念,在这里大家可以粗犷地理解成是“函数”,它包含对线程结构(grid-block-thread)的定义,以及结构中具体计算逻辑的定义。理解到这一层已不妨碍我们对flash attention的解读了,想要更近一步了解的朋友,推荐阅读这篇(https://zhuanlan.zhihu.com/p/34587739)文章。
kernel融合和尽可能利用起SRAM,以减少数据读取时间,都是flash attention的重要优化点。在后文对伪代码的解读中我们会看到,分块之后flash attention将矩阵乘法、mask、softmax、dropout操作合并成一个kernel,做到了只读一次和只写回一次,节省了数据读取时间。
好!目前为止所有的背景知识我们都介绍完了,现在我们直入主题,看看flash attention到底是怎么巧妙解决memory-bound问题。
四、Forward运作流程
在后文相关的讲解中,我们遵循以下步骤:
(1)先看Flash Attention做分块计算的整体流程。
(2)再看分块的计算细节。
(3)最后看Flash Attention是如何通过分块计算控制I/O,进而解决memory-bound的问题,提升整体运算速度。
4.1 标准attention计算
这个大家应该都很熟悉了,假设一共有个token,每个token向量的维度为,则一个标准的attention计算如下图:
其中,。在GPT类的模型中,还需要对做mask处理。为了表达方便,诸如mask、dropout之类的操作,我们都忽略掉,下文也是同理。
4.2 标准Safe softmax
这里我们需要额外强调这一步。正常来说,假设中某一行向量为,该行向量中的某一个元素为,则对做softmax后,有:
而如果过大,那么在计算softmax的过程中,就可能出现数据上溢的情况。为了解决这个问题,我们可以采用safe softmax方法:
下图展示了safe softmax的过程,这里分别表示做归一化前和做归一化后的结果。大家记住图中表达的含义,在后面的分块(Tiling)计算中,我们会用到这两个概念:
4.3 分块计算整体流程(Tiling)
我们知道Flash Attention的核心优化技术是采用了分块计算(Tiling),那么它是如何分块的?分块后的计算方式和不分块的计算方式又有哪些不同之处呢?
我们先来了解分块计算的整体流程(帮助大家理解数据块是怎么流转的),然后我们再针对其中的细节做一一讲解。
(1)首先,将矩阵切为块(block),每块的长度为。用来表示切完后的某块矩阵,则的维度为。不难理解,中存储着某个token的query信息。
(2)然后,将矩阵切为块,每块的长度为。用表示切完后的某块矩阵,则的维度为。易知中存储着某个token的key信息。
(3)同样,将矩阵也切为块,每块长度为。用表示切完后的某块矩阵,则的维度为。易知中存储着某个token的value信息。
(4)理解了上面的定义后,我们就可以开始做分块的attention计算了。以上图为例:
- 计算初始attention分数:,图中的表示前个token和前个token间的原始相关性分数。
- Safe softmax + mask + dropout:对做safe softmax、mask和dropout操作,得到。你可能会有疑惑:前面不是说,是归一化前的结果,是归一化后的结果吗?那么这里是不是应该用呢?这里确实只用算到,在后文对分块计算细节的讲解中,我们会详细说这点。目前为止,大家不用太纠结符号,只用大体知道代表的含义即可。
- 计算output:,即可得到输出结果。细心的你肯定又发现了,这个等式不太对劲,这个不太对劲。想一想,在正常情况下,前个token过attention后的输出结果,应该是它和所有token都做注意力计算后的输出结果。可是这里,却只是前个token和前个token的结果。虽然的shape对了,但其中的内容却不是我们最终想要的。所以,关于的计算,也是我们需要关注的细节,我们同样放在后文详说。
在计算这些分块时,GPU是可以做并行计算的,这也提升了计算效率。
好!现在你已经知道了单块的计算方式,现在让我们把整个流程流转起来把。在上图中,我们注明了是外循环,是内循环,这个意思就是说,对于每个,我们都把所有的遍历一遍,得到相关结果。在论文里,又称为K,V是外循环,Q是内循环。写成代码就是:
# ---------------------
# Tc: K和V的分块数
# Tr: Q的分块数量
# ---------------------
for1 <= j <= Tc:
for1 <= i <= Tr:
do....
如果你还有疑惑,那么下面两张图可以更直观地解答你的疑惑.,遍历:
,遍历:
【⚠️特别提醒】:正如上文所说,这里的还需要经过一定的处理,才能和不分块场景下的完全等价。这里我们将每一块的单独画出,是为了帮助大家更好理解分块计算的整体流程,不代表它是最终的输出结果。
好!到这一步为止,我们已经掌握了使用Tiling计算attention的整体框架。但我们依然有很多细节问题没有解决:
分块后,要如何正确计算attention score?(即的计算方法) 分块后,要如何正确计算输出? 分块后,是如何实现优化I/O,解决memory-bound的问题的?
4.4 分块计算中的safe softmax
回顾之前绘制的标准safe softmax流程图,我们知道都是针对完整的一行做rowmax、rowsum后的结果,那么在分块场景下,会变成什么样呢?
以上图红圈内的数据为例,在标准场景下,我们是对红圈内的每一行做rowmax、rowsum后得到的。
现在切换到分块场景,我们分别算出了和,然后我们再对它们分别做rowmax、rowsum,是不是也能得到和标准场景下一模一样的结果呢?
答案当然是否定的。举个简单的例子,标准场景下的是每行的全局最大值,可是分块后如果你也这么算,它就变成了局部最大值了。很明显,它不等同于标准场景下的结果。
所以,Flash Attention的作者们,在这里使用了一种巧妙的计算方式。
(1)我们假设标准场景下,矩阵某一行的向量为,因为分块的原因,它被我们切成了两部分。
(2)我们定义:
:标准场景下,该行的全局最大值 :分块1的全局最大值 :分块2的全局最大值
那么易知:
(3)我们定义:
:标准场景下,的结果 :分块场景下,的结果 :分块场景下,的结果
那么易知:
。这个很好理解,详细的证明过程就不写了。
(4)我们定义:
:标准场景下,的结果 :分块场景下,的结果 :分块场景下,的结果
那么由(3)易知:
(5)现在,我们就可以用分块计算的结果,来表示标准场景下safe softmax的结果了:
我们配合上面的图例和flash attention论文中的伪代码,再来进一步理解一下分块计算safe softmax的(1)~(5)步骤。
这里我们需注意:由于safe softmax是针对矩阵整行的计算,即相当于固定内圈,移动外圈的结果,所以在接下来的介绍中,我们都以这样的视角进行介绍。
我们用(图中浅绿色方块)替换掉(1)~(5)步骤中的,用(图中深绿色方块)替换掉。我们关注点在伪代码部分的5-11行。
由于伪代码中的表达符太多,容易阻碍大家的理解,因此我们先明确各个数学符号表达的含义:
- :对应在我们的例子里,就是和,即的结果
- :对于当前分块来说,每行的局部最大值。相当于前面步骤(2)中对的定义。
- :分块场景下,各块的P矩阵(归一化前)结果。相当于步骤(3)中对,的定义。
- :分块场景下,rowsum的结果。相当于步骤(4)中对,的定义。
- :标准场景下,对矩阵而言,每行的最大值,这是全局最大值(首次定义在伪代码第2行),相当于前面步骤(2)中对的定义
- :标准场景下,全局rowsum的结果(首次定义在伪代码第2行),相当于前面步骤(4)中对的定义。
- :表示。如果当前分块是,则表示固定时,前个分块中的局部最大值。容易推知,当固定,遍历完后,的结果就是全局最大值了。例如图例中,我们遍历完后,就能得到全局最大值。
- :表示。如果当前分块是,则表示固定时,截止到当前分块为止的局部最大值。
- :和对应,相当于步骤(4)中用分块更新的步骤。
- :和同理,即当我们将遍历完后,我们就能得到针对的全局rowmax和全局rowsum。而根据前面的定义,和是遍历完最新的后得到的rowmax和rowsum结果,所以每遍历完一块,我们就执行伪代码的第13行,做一次更新。
如果你被论文中这些数学符号乱花了眼,那再告诉大家一个理解它们的trick:
所有以作为下标的,都表示当前分块的计算结果 所有以作为下标的,都表示截止到前一个分块(包含前一个分块)的计算结果 所有以作为上标的,都表示引入当前分块做更新后的结果 所有没有下标的,都表示全局结果
相信通过上面对数学表发符的介绍,大家已经大致理解了分块计算safe softmax的过程,为了加深理解,现在我们再来读一遍伪代码,把整个流程串起来:
伪代码第5~7行:从HBM(显存)上读取到on-chip存储SRAM。注意,在代码处理逻辑上,这里是固定外圈,循环内圈。但是由于整个safe softmax逻辑是对“行”而言的,所以在理解时大家需要想像成固定内圈,循环外圈,也就是我们图例中绘制的深浅绿/蓝/黄色块。伪代码第8行:从HBM(显存)上读取。记住我们之前说的trick,下标带的都表示截止到前一个分块的计算结果。虽然我们前面没介绍过(在后文会细说),但按这个trick你应该也能猜到,也是随着分块的移动而逐步更新的。等移动到最后一个分块时,我们就能得到和标准场景下一模一样的输出结果。在之前的图例中,为了方便大家对分块的整体流程有快速理解,我们画了很多个出来,现在你应该能猜到,对每个,我们只维持并不断更新一个,直至遍历完毕(例如之前的图例中,我们画了6个,但实际我们要维护更新的,只有3个:)伪代码第9行:正常计算伪代码第10行:基于当前分块计算。特别注意,在之前标准场景的图解中,是已经除以后的结果,但这里是除以前的结果。除以的操作,放在伪代码第12行中了,也就是伪代码第11行:引入当前分块,计算截止目前为止的rowmax和rowsum,分别用表示。伪代码第12行:更新,后文会详细解析这部分公式伪代码第13行:用去更新
讲完了分块safe softmax的伪代码,这时你可能发现一个问题了:之前你是否一直以为,在这一顿操作后,分块计算得出的应该要和标准场景下的完全一致(比如应该是我们步骤(1)~(5)介绍的那样)?但是现在看来,每个分块依然是用自己局部的rowmax和rowsum做计算的,并没有达到我们理想中的效果呀!
别急,还记得伪代码第12行我们说的更新的公式么?分块计算的真正意义不在于得到正确的,而在于得到正确的。
然后,你再来看伪代码5-13行,你会发现,在整个计算过程中,只有被从on-chip的SRAM中写回到显存(HBM)中。把都遍历完后,读写量也不过是。相比于标准场景下,我们要读写的是,读写量是不是一下就少很多,这不就能解决memory-bound的问题了吗。
所以,分块计算safe softmax的意义,就是抹去对的读写。
4.5 分块计算中的输出O
终于到翘首以盼的输出的分析部分了,当你第一次看到伪代码12行更新的公式,是不是觉得两眼一黑?不要紧,这里我们依然通过图解的方式,帮助大家理解并推导这个公式。
之前我们说过,上图中画的6个并不是我们最终想要的结果。我们期望维护并更新,当该下的所有遍历完毕后,我们的就应该和标准场景下的完全相等。
回到图例中,图中的就应该等于被红框圈起来的部分和部分的乘积。但是别忘记之前说过,这里各块都是局部rowmax,rowsum计算出来的结果。所以我们必须对各块再做一些处理,才能让它们和V相乘,更新。
那么要处理到什么程度为止呢?第一想法可能是,只要让每块结果和标准场景下的结果完全一致,不就行了吗?但是别忘了,你不计算到最后一块,你是拿不到全局的rowmax和rowsum的。而由于为了解决memory-bound的问题,我们只保留而不存各块。因此等你遍历到最后一块时,虽然有了全局的rowmax和rowsum,但没有,你根本算不出最终的。
所以这里我们换个思路:不是每遍历一块就更新一次吗?那有没有一种办法,不断用当前最新的rowmax和rowsum去更新,直到遍历完最后一块,这时的不就和标准场景下的结果完全一致了吗?也就是我们想构造形如下面这样的更新等式:
沿着这个思路,我们来看伪代码第12行公式的诞生过程:
初次看到这个推导过程,你可能有些懵圈,不要紧,我们一行一行来看。在讲解之前,我们先明确以上推导过程中符号上下标的含义:
:这个大家应该很熟悉了。例如图例中,分别对应着深浅绿、深浅蓝、深浅黄块。 :表示当前分块的相关结果 :表示截止到当前分块(包含当前分块)的相关结果。表示截止到前一分块(包含前一分块)的相关结果。
(1)第一行:
首先,我们期望的结果是,每遍历一个分块,就更新一次,遍历完全部的分块后,我们就能得到和标准场景下完全一致的。基于此我们有。其中,表示从第0个分块到当前分块,我们用当前最新的rowmax,rowsum更新一次
所有分块的
结果(因为做过归一化了,所以是不带波浪号的
)。
则表示当前分块及之前所有分块所对应着的
部分(例如图例中,若当前分块是浅绿色块,则其对应着浅灰色
;若当前分块是深绿色块,则其对应着浅灰色+深灰色
)。
(2)第二行:将
改写成
的形式。
特别注意,这里所代表的各个分块间都是相互独立的,你可以理解为,只有在做
这个操作时,才考虑对这些独立的
用最新的rowmax,rowsum去更新
。
(3)第三行:就是把(2)当中的
展开写了。即用当前最新的rowmax和rowsum去计算
。这里将
拆成
两部分([之前所有的分块,当前分块])。同理拆
。
(4)~(5)第四~五行:做简单的变式,不再赘述。
(6)第六行:我们观察到,中括号式子里的前半部分,和之前所有分块的结果密切相关。联想到我们最终的目标是不断更新,也就是在上一个的基础上,引入当前分块的信息做更新。因此,能不能把上一个(对应到我们的式子里就是)表达出来呢?
基于这个思想做递推,
当然就是
之前的所有分块,用
上一分块的rowmax、rowsum做更新后求得
,再乘上对应的
得到的结果呀,所以根据此我们攒出了
这一项(就是
),然后再用
去抵消我们在攒它的过程中引入的项。
(7)~(9):第七~九行:明确了(6)以后,剩下的部分就很好理解啦。这里额外说下,为什么要把
放进去呢(毕竟有了
都是已知的,已经可以算了)。因为我们在求解rowsum相关的数据时,还是要把数据从
转为
才能求,因此避不开算
。另外也是为了让表达起来更统一,因此这里引入
,进而引入
进行计算(7中P无波浪号,公式typo)
现在再回头看伪代码的第12行,是不是就很清楚了呢?
建议大家可以自行画图,动手推导,加深理解。五、Backward运作流程
5.1 softmax求导
在后文对分块计算backward中,我们会频繁接触到和softmax求导相关的知识,繁杂的数学符号可能会使很多朋友看得蒙圈,所以这里我们做个快速复习。
设
其中,表示Loss,表示Loss函数,
,若现在我们想求,要怎么算呢?根据链式法则,我们有
,所以我们分别来看这两项。
(1)
我们现在不考虑具体的Loss函数,直接假设这一项的结果为
(2)
我们知道,对于某个来说,在softmax的操作下,它参与了三者的计算,因此它的偏导也和这三者密切相关,这里我们分成两种情况:
根据这个结果,我们有:
这里代表向量中一共有几个要素,例如在本例中,。假设我们现在要求,则根据上述公式,我们有:
这里不再赘述详细的推动过程,有需要的朋友可以参考https://www.cnblogs.com/wuliytTaotao/p/10787510.html这篇文章。
有了这个理解,我们再来谈谈基于的Jacobian矩阵:
很容易发现只要把每行/每列相加,就能得到对应
的偏导。别着急求和,我们继续往下看。
(3)
有了(1)(2)的结果,现在就可以来推导,我们有:
举个例子,若我们现在想求,我们将
代入上面公式,则有:现在,针对所有的,我们将写成矩阵表达式有:
至此,大家记住这两个重要的结论:
5.2 标准backward计算
我们先来总结下forward中做的操作,为了表达简便,这里将mask、dropout等零碎操作省去,同时假设是损失函数:
对于标准backward来说,在计算开始时,显存(HBM)上已经存放有这些数据。论文中的伪代码已经介绍得非常清楚,大家可以自行阅读,这里就不赘述了。对伪代码第3行求有困惑的朋友,可见上文“softamx求导”部分。
5.3 分块backward计算
在讲解backward计算前,我们先来看看经过分块Forward计算后,显存(HBM)上都存了哪些数据:
:全局rowmax :全局rowsum :等同于标准attention场景下的结果 :等同于标准attention场景下的输出结果 :有了完整的,我们就可以按正常的backward步骤先求出它的梯度,也存放在显存上。然后我们就能按照链式法则,分块地去求别的矩阵的梯度了。
既然有了全局的和,那么现在对于任意一块,我们就能基于算出和标准场景下完全一致的了。因此,在backward的过程中,flash attention将采用重计算的方式,重新算出,并将它们运用到backward的计算中去,所以在接下来的讲解中,大家就可以把理解成完全等同于标准场景下的结果,而不是像分块计算forward中那样的。
另外需要注意的是,为了简化表达,在接下来的分析中,关于mask、dropout之类的步骤,我们在表述上都略去。现在让我们来看分块计算backward的伪代码:
(1)求梯度
由Forward过程我们知:,因此有了后,我们就可以先来求和了。观察下方的图,我们会发现此时所有的都是不带波浪号的,再强调一下,这是因为经过了重计算,此处的结果都等同于标准场景下的结果,而不是forward中所代表的含义。
假设现在,那我们要怎么求呢?
我们先来看都参与了哪些部分的计算,以及是怎么参与的:由图可知,和参与了的计算,和参与了的计算,和参与了的计算。所以我们有:
进而推知:
在伪代码11~15行中,做的都是重计算的过程,伪代码的第16行,就是在按这个方法分块计算并累积。
(2)求梯度
观察上图,可以发现只与相关,例如只与相关。因此我们有:
这就是伪代码第17行做的事情。
(3)求梯度
这一块是令许多人感到迷惑的,我们先来回顾下“softmax求导”部分让大家记住的一个重要结论:
我们假设分别为矩阵的某一行(注意这里不是表示第块的意思,是表示第行,所以我们用小写的表示),那么根据这个结论,我们有:
你可能对这个推导的最后一步有疑惑:为什么要大费周章,将改写成这么复杂的形式呢?因为在最后一步之前,我们都是针对“某一行”来求导,而引入最后一步的目的,是为了延展至对“某一块(多行)”的求导,也就是说针对某一块(注意这里是大写的,的含义也回归至“第几块”),我们有:
如果实在难以理解推导过程,建议大家可以带一些具体的值进去,就能理解我们为什么要写成这种形式了。进而,我们可以推知:
这就是伪代码第19~20行做的事情。
(4)求梯度
到目前为止,我们已经知道,那么现在就可以根据链式法则继续求了。
对照上图,我们把目光聚焦在身上,由forward过程可知:
因此,针对,我们有:
推广到任意,我们有:
这就是伪代码第21行做的事情。
(5)求梯度
这一步就很简单啦,如果你被复杂的分块推导弄懵了脑袋,那不妨再复习一下我们前面提过的trick:对照上图,取出某一块。由于我们是从链式推向,所以这里只要搞明白这块和哪些一起计算出了哪些$再把相关结果相加即可。
只要看了流程图,就不难得知:某块和对应的共同计算出了对应的,因此有:
这就是伪代码第22行做的事情。
好!现在我们就把分块backward的细节讲完了,当大家感到迷茫时,一定记得画图;在碰到需要做累加才能计算出梯度的步骤中,画图也可以帮助我们快速理解是按维度还是按维度进行累加。
六、计算量和显存需求
6.1 矩阵相乘的计算量
我们先来看一个前置知识:两个矩阵相乘,要怎么统计它们的计算量?
我们一般用FLOPs(floating point operations,浮点运算次数)来表示运算量的大小。对于“两矩阵相乘”这个操作而言,其运算量 = 乘法运算的次数 + 加法运算的次数。
来看一个具体例子:
两矩阵相乘,为了获取图中深橘色部分的元素,我们一共需要进行n次乘法运算和n-1次加法运算。
那么现在结果矩阵中,一共有m*p个橘色方块,则意味着我们需要进行:
m*p*(n + n - 1)次浮点计算。再进一步,假设此时在蓝色和绿色的矩阵外,我们还有一个bias矩阵,意味着计算单个橘色方块时我们需要进行n次乘法和n-1+1次加法运算,那么此时总计算量为:
m*p*(n+n) = 2mnp。当然,即使不加这个bias,我们也可以把-1项给忽略,得到相同的结果。所以这里我们总结下,假设有两个矩阵A和B,它们的维度分别为(m, n)和(n, p),则这两矩阵相乘的运算量为
2mnp。一般在矩阵运算中,乘法运算的时间要高于加法运算的时间,因此有时在统计运算量时,我们只考虑乘法运算的次数,则此时两矩阵相乘的运算量可近似为mnp
6.2 Flash Attention的计算量
有了前置知识,我们就能分析flash attention的计算量了,我们以forward过程为例(为了大家阅读方便,我们再把forward的伪代码放一遍):
我们知道矩阵相乘运算占据了运算量的大头,因此我们把分析目光集中到所有的矩阵运算上来。
(1)在代码第9行,我们有,其中。根据前置知识,求的计算量为。
(2)在代码第12行,我们有,其中。则这里的计算量同样为
(3)接下来我们看一共计算了多少次(1)和(2),也就是执行了多少次内循环:。
(4)综合以上三点,flash attention的forward计算量为:,注意,因为计算量是用大O阶表示的,所以这里我们把常数项都省略了。
同理大家可以自行推一下backward中的计算量,在论文里给出的结论是,d远小于N,因此也可以略去不表达。
6.3 Flash Attention的显存需求
和标准attention相比,如果不考虑的话,Flash Attention只需要存储,其显存需求为。
而标准attention需要存储,其显存需求为。
可以发现相比于标准attention,flash attention明显降低了对显存的需求。
七、IO复杂度
之前我们强调过,flash attention相比于标准attention的最大优势,就是其减少了对显存(HBM)的访问次数,一定程度上解决了memory bound的问题。所以这一节我们就来具体分析这两者对显存的访问次数(同样都是以forward为例,backward部分论文中也有给出相关推导过程,大家可以类比forward自行阅读)。
7.1 标准attention的IO复杂度
(1)从HBM中读取,计算并将写回HBM。一读一写的IO复杂度为:,在表示大O阶时我们忽略常数项。
(2)从HBM中读取,同时计算并将其写回HBM。一读一写的IO复杂度为:。
(3)从HBM中读取,计算并将写回HBM。一读一写的IO复杂度为:
所以,总体来说标准attention的IO复杂度为:
7.2 Flash attention的IO复杂度
(1)我们来看伪代码的第6行,在每个外循环中,我们都会加载的block。所有外循环结束后,相当于我们加载了完整的,因此这里的IO复杂度为:
(2)再看伪代码第8行,在每个内循环中,我们都加载了部分 block,由于本身比较小(IO复杂度是),因此我们暂时忽略它们,只考虑(原论文也是这么分析的)。固定某个外循环,所有内循环结束后,我们相当于完整遍历了。同时我们会经历次外循环。因此这里最终的IO复杂度为:。
(3)将写回HBM,这里近似后IO复杂度为:。不过在原论文的分析中并没有考虑写回的复杂度,不过省略一些常数项不会影响我们最终的分析。
所以,总体来说flash attention的IO复杂度为:
论文中提过,一般d的取值在64~128,M的取值在100KB左右,因此有。因此可以看出,Flash attention的IO复杂度是要显著小于标准attention的IO复杂度的。
八、实验效果
Flash attention的作者将的GPT2-medium部署在A100 GPU上,来观测采用flash attention前后的模型的计算性能。
我们先看最左侧图表,标准attention下,计算强度,说明GPT2在A100上的训练是受到内存限制的。而在采用flash attention后得到了明显改善,runtime也呈现了显著下降。
我们再来看中间的图表,它表示在使用flash attention的前提下,以forward过程为例,每个数据块的大小对HBM读写次数(绿色)和耗时(蓝色)的影响。可以发现,数据块越大,读写次数越少,而随着读写次数的减少,runtime也整体下降了(复习一下,读写复杂度为,数据块越大意味着越小)。但有意思的是,当数据块大小>256后,runtime的下降不明显了,这是因为随着矩阵的变大,计算耗时也更大了,会抹平读写节省下来的时间。
九、参考
1、https://arxiv.org/abs/2205.14135
2、https://leimao.github.io/blog/Math-Bound-VS-Memory-Bound-Operations/
3、https://zhuanlan.zhihu.com/p/639228219
4、https://zhuanlan.zhihu.com/p/638468472
5、https://zhuanlan.zhihu.com/p/651179378
6、https://zhuanlan.zhihu.com/p/462191421
7、https://zhuanlan.zhihu.com/p/34587739
8、https://zhuanlan.zhihu.com/p/34204282
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。