微软亚洲研究院提出全新大模型基础架构RetNet,或将成为Transformer有力继承者!
(本文阅读时间:4分钟)
作为全新的神经网络架构,RetNet 同时实现了良好的扩展结果、并行训练、低成本部署和高效推理。这些特性将使 RetNet 有可能成为继 Transformer 之后大语言模型基础网络架构的有力继承者。
——韦福如
微软亚洲研究院全球研究合伙人
以下内容经授权转载自公众号“量子位”,原文标题《Transformer后继有模!MSRA提出全新大模型基础架构:推理速度8倍提升,内存占用减少70%》。
今天,微软亚洲研究院上线了大模型新架构的论文“Retentive Network: A Successor to Transformer for Large Language Models”,该基础架构采用了新的 Retention 机制来代替 Attention,向 Transformer 发起挑战!
实验数据也显示,在语言建模任务上:
RetNet 可以达到与 Transformer 相当的困惑度(perplexity) 推理速度达8.4倍 内存占用减少70% 具有良好的扩展性
并且当模型大小大于一定规模时,RetNet 的表现会优于 Transformer。
具体详情,一起来看。
Transformer 在大语言模型中的重要性毋庸置疑。无论是 OpenAI 的 GPT 系列,还是谷歌的 PaLM、Meta 的 LLaMA,都是基于 Transformer 打造。
但 Transformer 也并非完美无缺:其并行处理机制是以低效推理为代价的,每个步骤的复杂度为 O(N);Transformer 是内存密集型模型,序列越长,占用的内存越多。
在此之前,大家也不是没想过继续改进 Transformer。但主要的几种研究方向都有些顾此失彼:
线性 Attention 可以降低推理成本,但性能较差;
循环神经网络则无法进行并行训练。
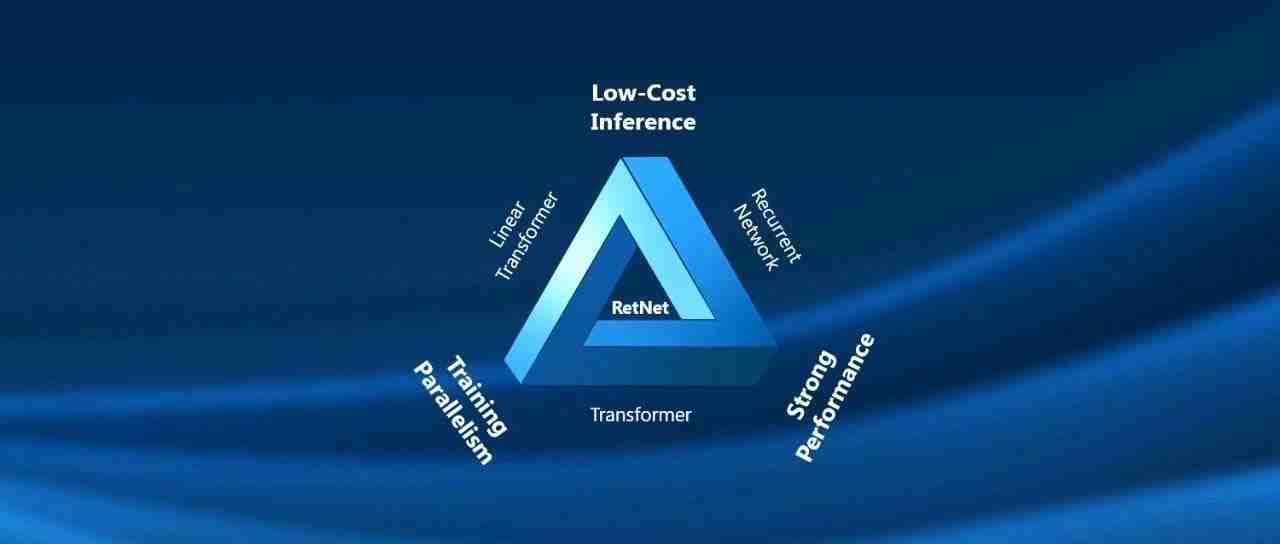
也就是说,这些神经网络架构面前摆着一个“不可能三角”,三个角代表的分别是:并行训练、低成本推理和良好的扩展性能。
RetNet 的研究人员想做的,就是化不可能为可能。
具体而言,RetNet 在 Transformer 的基础上,使用多尺度保持(Retention)机制替代了标准的自注意力机制。
与标准自注意力机制相比,保持机制有几大特点:
引入位置相关的指数衰减项取代 softmax,简化了计算,同时使前步的信息以衰减的形式保留下来。
引入复数空间表达位置信息,取代绝对或相对位置编码,容易转换为递归形式。
另外,保持机制使用多尺度的衰减率,增加了模型的表达能力,并利用 GroupNorm 的缩放不变性来提高 Retention 层的数值精度。
RetNet 的双重表示
每个 RetNet 块包含两个模块:多尺度保持(MSR)模块和前馈网络(FFN)模块。
保持机制支持以三种形式表示序列:
并行 递归 分块递归,即并行表示和递归表示的混合形式,将输入序列划分为块,在块内按照并行表示进行计算,在块间遵循递归表示。
其中,并行表示使 RetNet 可以像 Transformer 一样高效地利用 GPU 进行并行训练。
递归表示实现了O(1)的推理复杂度,降低了内存占用和延迟。
分块递归则可以更高效地处理长序列。
这样一来,RetNet 就使得“不可能三角”成为可能。以下为 RetNet 与其他基础架构的对比结果:
在语言建模任务上的实验结果,进一步证明了 RetNet 的有效性。
结果显示,RetNet 可以达到与 Transformer 相似的困惑度(PPL,评价语言模型好坏的指标,越小越好)。
同时,在模型参数为70亿、输入序列长度为8k的情况下,RetNet 的推理速度能达到 Transformer 的8.4倍,内存占用减少70%。
在训练过程中,RetNet 在内存节省和加速效果方面,也比标准 Transformer+FlashAttention 表现更好,分别达到25-50%和7倍。
值得一提的是,RetNet 的推理成本与序列长度无关,推理延迟对批量大小不敏感,允许高吞吐量。
另外,当模型参数规模大于20亿时,RetNet 的表现会优于 Transformer。
Retentive Network: A Successor to Transformer for Large Language Models
论文地址:
https://arxiv.org/abs/2307.08621
你也许还想看:
关键词
架构
大模型
结果
同时
研究院
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。