DataJob入门 — 在 AWS 上构建和部署无服务器数据管道



今日份知识你摄入了么?
数据工程师的核心工作包括了构建、部署、运行和监控数据管道。
但在数据和 ML 工程领域工作时,缺少一种工具,用于简化在 AWS 服务(如 Glue 和 Sagemaker)上部署数据管道过程,以及轻松通过 Step Functions 编排数据管道步骤。所以, DataJob诞生了!

图源:https://unsplash.com/photos/Q1p7bh3SHj8
在本文中,我将向你演示如何安装 DataJob,通过简单示例给予指导,展示 DataJob 的某些功能。
你可以在 PyPI 中安装 DataJob。DataJob 通过 AWS CDK 配置 AWS 服务,所以一定要安装此服务。如果你想动手实践本文的这个示例,你需要一个 AWS 账户 。
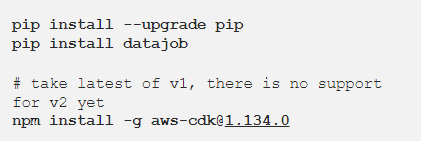
该工具包含一个简单的数据管道,由 2 个打印“Hello World”的任务组成,这些任务需要按顺序进行编排。DataJob将这些任务部署到 Glue,并通过阶梯函数(Step Functions)进行编排。

我们将上述代码添加至项目根目录下名为 datajob_stack.py 的文件中。此文件包含配置 AWS 服务、部署代码和运行数据管道所需内容。
接着,克隆(Clone)存储库,并回到本例中。

要配置 CDK,你需要 AWS 的凭据。如果你不知道如何配置 AWS 凭据,请按照以下步骤操作。
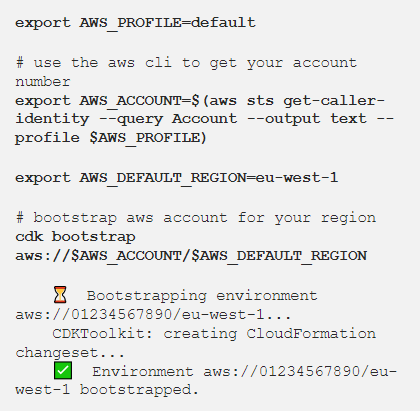
使用包含代码的 Glue 任务,将编排 Glue 任务的 Step Functions 状态机创建 DataJob 堆栈。

当 cdk deploy 完成时,准备执行已配置好的服务。

触发编排数据管道的阶梯函数状态机(Step Functions state machine)。
终端将显示阶梯函数网页链接,以跟进管道运行情况。如果单击此链接,你应该会看到如下内容:
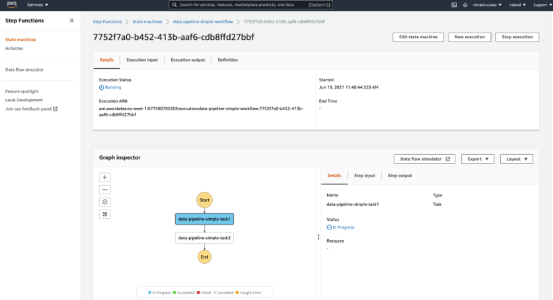
数据管道完成后,将其从 AWS 中删除。这样,你将拥有一个干净的 AWS 账户。

- 1. 使用 Glue Pyspark 任务处理大数据
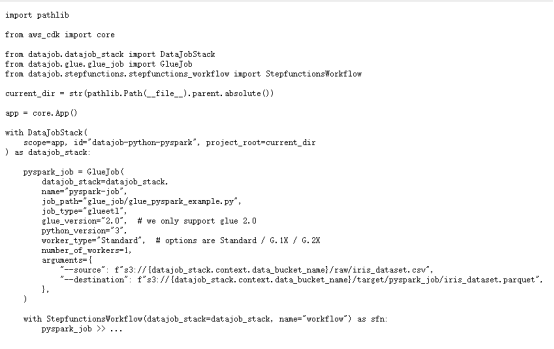
- 2. 部署独立管道
在CDK中指定一个阶段作为上下文参数,部署一个独立管道。经常用到的有dev, prod,…

- 3. 并行编排 Step Function 任务
为了加速数据管道,您可能希望并行运行任务。DataJob可以帮助你执行此操作!我借用了 Airflow 的概念,您可以使用运算符 >> 协调不同的任务。
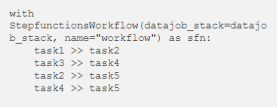
DataJob 计算哪些任务可以并行运行,从而加快执行速度。
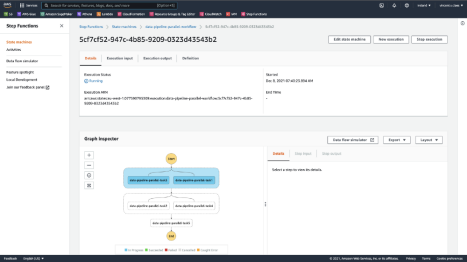
部署并触发后,你将在步骤函数执行中看到并行任务。
- 4. 失败/成功时通知
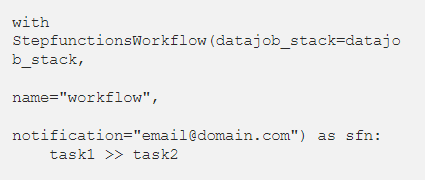
在 StepfunctionsWorkflow 对象的构造函数中,提供带有电子邮件地址的参数notification。这会创建一个 SNS 主题,该主题将在失败或成功时触发,同时收件箱会收到通知。
- 5. 将项目打包为Wheel文件,并将其发送到 AWS
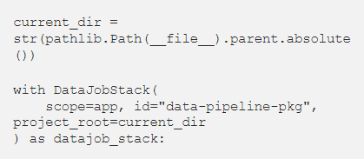
将项目及其所有依赖项发送到 Glue。通过在 DataJobStack 的构造函数中指定 project_root,DataJob 将在你的 project_root 的 dist/ 文件夹中查找Wheel文件(.whl 文件)。
- 6. 添加 Sagemaker,创建 ML Pipeline
通过 Glue、Sagemaker 和 Step 函数,可以查看 GitHub 存储库上端到端机器学习管道的新示例。
感谢你的阅读!你会尝试这个新工具吗?请在评论中告诉我您的想法。
原文作者:Vicent Claes
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/datajob-build-and-deploy-a-serverless-data-pipeline-on-aws-18bcaddb6676
公开课预告

往期精彩回顾



点「在看」的人都变好看了哦

点击“阅读原文”查看数据应用学院核心课程
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。