数据科学家面试,我被问到这六个问题



今日份知识你摄入了么?
近年来,数据科学实现跨越式发展。因此,数据科学家的需求大幅增加,许多人转行从事该领域的工作。
这一系列事件都不得不经历一个流程—面试。只有雄心抱负,你是无法找到心仪的工作的。要想成为一名合格的数据科学家候选人,你需要掌握一系列的技能。
数据科学是一个跨学科领域,因此所需的技能并不集中在某个主题上。在本文中,我将分享在数据科学家面试中经常出现的 6 个问题。

图源:Unsplash 摄影:Scott Graham
我选择的问题涵盖了不同的主题,这样你就可以大致了解在数据科学家的面试中会出现哪些问题,主要涉及Python、机器学习、SQL和数据库。
同时,本文还包含问题答案,从广泛的意义上讨论这些主题。
问题 1:L1 和 L2 正则化技术是什么,有什么区别?
在机器学习中,当模型尝试拟合训练数据,导致无法推广到新的观察结果,就会出现过度拟合。过度拟合模型捕捉训练数据中的细节和干扰项,而非总体趋势。因此,过度拟合的模型虽然在训练数据上表现非常出色,但在原来无法看到的新观察结果上表现不佳。
过度拟合出现的主要原因是模型的复杂性。
正则化(Regularization)通过惩罚模型中的较高项,控制模型的复杂性。如果在模型中添加正则化项,则可以尽量减少模型的损失和复杂性。
导致模型复杂的两个主要原因是:
- 特征的数量(由 L1 正则化处理),或
- 特征的权重(由 L2 正则化处理)
L1 正则化,也称为稀疏性正则化(Regularization for Sparsity),用于处理主要由零组成的稀疏向量。L1 正则化通过在每次迭代时从权重中减去一部分,从而迫使无信息特征的权重等于零,最终使权重等于零。
L2 正则化,也称为简化正则化(Regularization for Simplicity),迫使权重趋于零,但并完全等于零。L2正则化就像一个力,在每次迭代中减去一小部分权重。因此,权重永远不会等于零。如果我们将模型复杂度视为权重的函数,那么特征的复杂度与其权重的绝对值成正比。
总的来说,L1 正则化惩罚的是 |权重|,而 L2 正则化惩罚的是
(权重)²。
问题2:分类
(Classification)和聚类
(Clustering)有什么区别?
分类和聚类是两种不同的机器学习任务。
分类(Classification)是一种监督式学习任务。分类任务中的样本有标签。每个数据点都根据测量进行分类。分类算法试图根据样本的测量值(特征)与其指定类别之间的关系进行建模。然后,将该模型用于预测新样本类别。
聚类(Clustering)是一项无监督式学习任务。聚类中的样本没有标签。该模型用于在数据集中找到结构,以便将相似的样本分组到集群中,从而标记样本。
问题 3:假设有一个元组列表,如何根据元组中的第二项对列表进行排序?
这是一个编程问题。我们最经常使用Python。我们有以下元组列表,需要根据元组中的第二项进行排序。

我们有两个方法可选。第一个选项是返回原始列表的排序版本,这样原始列表不会被修改。

第二个选项是就地排序,意味着原始列表将被修改。

问题 4:Python 中的“yield”关键字有什么用?
在 Python 中,如果我们可以用循环或推导式
(例如列表、字典)迭代元素,那么该对象就是可迭代对象。
生成器是一种特定的可迭代器。生成器不会将值存储在内存中,因此,我们只能迭代一次。这些值是在迭代时生成的。
yield 关键字可以用作函数中的返回关键字。不同之处在于,如果使用 yield 关键字而非 return,那么该函数将返回一个生成器。
当该函数返回一组只会被使用一次的值时,证明该函数非常有用、高效。
当一个函数包含 yield 关键字,该函数就变成了生成器函数。换句话说,yield 将函数转换为生成器,以便逐个返回值。
问题 5:什么是数据库中的规范化
(Normalization)和非规范化
(Denormalization)?
两者都是在设计数据库时使用的技术。
规范化的目标是减少数据冗余和数据不一致。表的数量随着规范化而增加。
非规范化的目标是通过添加冗余,更快地运行查询。表的增加数量低于规范化技术。
假设我们在为零售业务设计数据库。存储的数据包含客户数据(姓名、电子邮件地址、电话号码)和购买数据(购买日期、购买金额)。
规范化技术建议使用单独的表存储客户数据和购买数据。这些表可以通过使用外键(如客户ID)进行关联。在这种情况下,当客户数据(例如电子邮件地址)出现更新,我们只需更新客户表中的一行。
非规范化技术建议将所有数据放在表中。当需要更新客户的电子邮件地址,我们需要更新包含该客户购买的所有行。与规范化相比,非规范化的优点是可以更快地运行查询。
问题 6:SQL 查询
你很有可能会遇到有关 SQL 查询的问题。如果在面试官要求你根据给定的查询,编写 select 语句,从表中检索数据。
假设我们有以下项目表。
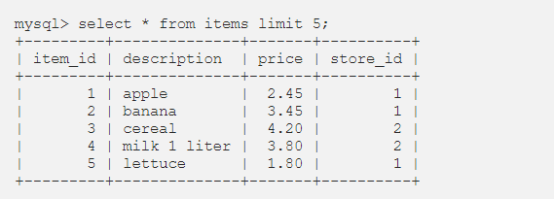
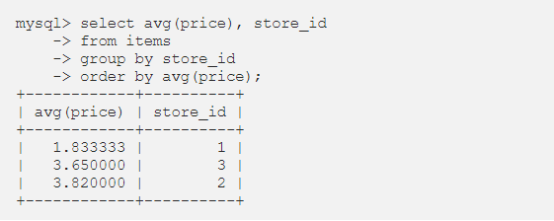
查找每家商店商品的平均价格,并按平均价格对结果进行排序。我们可以通过将 avg 函数应用于价格列,并按商店 ID 对值进行分组,解决这个问题。通过在末尾添加order by 子句,对商店进行排序。

结论
以上都是我在面试中实际被问到的问题。你可能不会遇到一样的问题,但主题基本上都一样。
需要注意的是,这些问题可能来自不同的领域。这也表明对数据科学家的不同要求。拥有多种技能将帮助你在竞争激烈的就业市场中领先一步。
感谢你的阅读。如果你有任何反馈,请在评论中告诉我。请继续关注即将发布的文章!
原文作者:Soner Yidirim
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/6-questions-i-was-asked-at-data-scientist-interviews-39a095d87c6c
公开课预告

往期精彩回顾



点「在看」的人都变好看了哦

点击“阅读原文”查看数据应用学院核心课程
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。