大数据对商家是个宝,对顾客或许是把刀!“大数据杀熟”,你被宰过吗?

长按二维码,“识别图中小程序码”,解放眼睛!收听此文章的音频!

文 | 闫坤沐
编辑 | James
律师李欣然(化名)第一次对某旅行票务网站产生警觉是在去年暑假。为了带女儿去日本迪士尼,她相中一家酒店,但
同一个房型,在她手机上显示的价格比在丈夫手机上贵120元人民币。
刚开始,李欣然还以为是丈夫没选三人同住的缘故,但仔细核对后发现并不是。她向婆婆要来手机,以新客人的身份下载注册了同一款APP,还很严谨地用流量而不是家里WiFi联网,查询后发现,甚至一些房间比丈夫手机上显示的价格还要更低。
“搜索以后的结果直接就有差异,我并没有领优惠券也没有收到红包。”
因为工作原因,李欣然出差频繁,经常用APP给自己订商务型酒店。尽管不清楚具体的技术原理,但她凭直觉推断,自己是被平台的用户画像识别成了消费能力高的客户,所以会给她显示更高的价格。
在网络上,和李欣然一样因为感受到被区别对待的人不在少数,他们的集体控诉而产生了一个新的概念:“大数据杀熟”。概念发明后,更多的网友开始把自己的经历对号入座。

几乎没有一个互联网产品不被怀疑“杀熟”——
有人说在电影购票APP里花钱买了会员,票价反而比非会员更高;有人察觉到用旅行APP买机票,只要你没付钱,价格越搜越贵,余票越来越少,直到只剩一张,吓得你赶紧付钱。可等付了钱再搜,这张机票还能买,而且又跌回了原来的优惠价。有人发现同样是买一年的视频网站会员,iPhone用户比Android手机用户多花几十块钱;
舆论风暴中,携程大住宿事业部CEO陈瑞亮接受采访,以职业身份向用户保证,自家平台上没有过也不会有大数据杀熟的现象发生。他解释不同用户间显示的差价是优惠券造成的。
也就是说:做不做“大数据杀熟”,全凭公司自觉;但如果一家公司决定这么做,用户要付出很大的代价。
斗智斗勇
但李欣然觉得,这听起来显然非常不“互联网”。
她察觉到房间价格异样时,出于职业习惯,她敏锐地意识到了一个比“杀熟”更深层次的问题:我使用的APP,在试图了解和定义我。
“如果一个APP能判断我和我婆婆对价格的承受能力不同,那它一定知道我更多信息。”
携程技术中心高级研发经理周源曾写过一篇文章叫《手把手教你用大数据打造用户画像》,其中透露出来的一些信息,从侧面验证了李欣然的猜想。
据周源介绍,携程对用户数据的采集不仅来自于自家网站和APP,同样也会抓取合作站点。他们为用户建立画像的维度包括年龄、性别、消费能力、亲子偏好等等,“数据是海量的”。
文章中的一个图表显示,携程根据用户的消费能力定义划分为“非常小气、一般小气、一般大方、非常大方”四个等级。
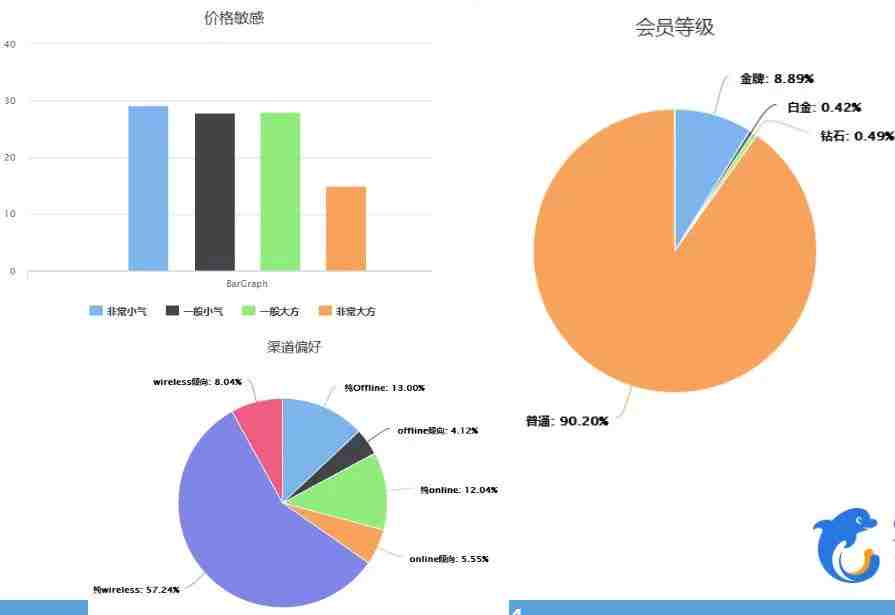
《手把手教你用大数据打造用户画像》一文中使用的图表
事实上,差别定价并不是什么了不起的新鲜技术,亚马逊早在2000年9月就实施过类似的实验。他们选择了68款DVD碟片,根据用户填写的资料、购物历史、上网使用的操作系统等条件判断他们的购买力,给他们输出不同的价格。一个20美元出头的产品,新用户和老用户之间差价波动在4美元左右。
这个实验进行了不到一个月,就被用户发现了。成百上千的网友通过发布自己买到的产品价格做人工比价,愤怒之余,讨论层面不可避免地上升到怀疑亚马逊在收集和分析用户的隐私数据,以至于当时的CEO不得不站出来保证,亚马逊永远不会对用户区别定价。
18年之后的中国,几乎类似的情境发生在更多公司身上,并且远远不止于此。
“大数据杀熟”刷屏之后,知乎用户“逻格斯”又提出另一个更可怕的假设叫“大数据售假”:如果消费行为大数据显示你是一个不爱写评价,几乎不会给出差评的用户,那某些真假混卖的电商平台,他们可以依据这项数据把假货发给你。”
作为一个对维权很敏感的人,李欣然开始关注与大数据斗智斗勇的方法。她弃用了大多数APP,重新回到网页时代,并使用浏览器的隐身模式,不在电脑或者手机上留下访问网站的痕迹,还养成了手动清理cookie记录的习惯,以及使用任何服务之前都会货比三家。
和李欣然一样,更多网友试图研究“调戏”大数据的方法。
我昨天在A平台上打算买一桶油,下单前临时刹车,去B平台上看了一眼,B平台比A平台的会员价还便宜,于是把B平台的油加入购物车,再删除了A平台的购物车。然后,我再打开A平台,它给我发了一张粮油优惠券。
这样的试验或许有玩笑成分,但也反映了在大数据面前,一个普通用户想要保护自己的利益和隐私需要付出高昂的成本。
为何要杀熟
这是一种价格歧视,是商家压榨消费者剩余的手段,可以用一张简单的图片来辅助理解。
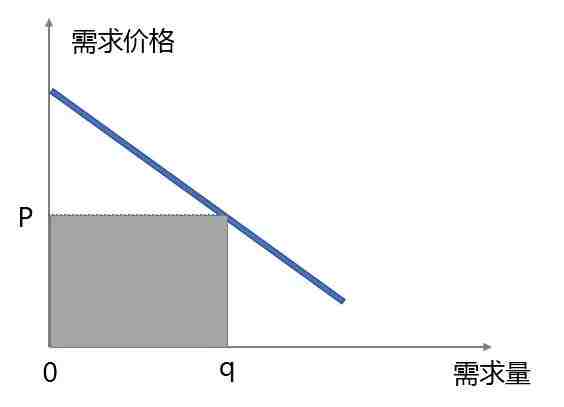
需求价格和需求量成反比关系。理论上存在一个价格点,刚好使得需求量等于厂商的供给量。这个时候厂商的营收就是上图的阴影部分。
但是对于厂商来说,这不是最佳的策略,最佳的策略是用价格歧视。
例如这张图中有两个人A、B,他们的需求价格分别是P1、P2。
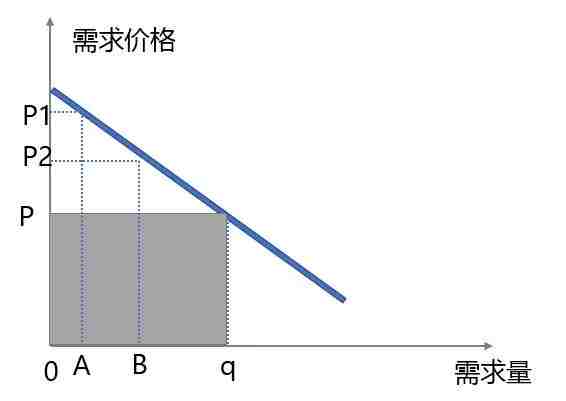
如果能让A花P1的钱来买这件产品,B花P2的钱来买这件产品。那自然会比单纯卖P价格能赚更多的钱。而能让所有用户刚刚好用自己的心里预期买下那件产品,那么厂商最后的营收会变成这样:

通过一段段的价格歧视,厂商能赚最多的钱,这才是厂商的最佳策略。而其中的蓝色三角形,就是我们说的消费者剩余。
更为恐怖的是,这件事情在万物互联的时代,变得非常非常简单。
抵抗和伪装都是徒劳
对大数据的恐慌情绪愈演愈烈,也催生出很多错觉和谣言。
最典型的一个,是怀疑自己被监听。你一定听朋友讲过这样的“恐怖”故事:我前脚聊天时和别人讨论了去海边旅行,后脚打开购物APP就发现它在给我推荐泳衣。我什么都没搜,它是怎么知道我想干什么的?难道是利用麦克风权限在监听我?
事实上,如果人工智能真的能做到这么“智能”,别说手机抗不扛得住电量,市面上的语音识别服务也不至于还在错漏百出的阶段了。
公众的误解在于,比起监听,其实你手机里的APP有一万种性价比更高的方式了解你,而你几乎难以察觉。
以几乎每个APP都要求开放的位置授权举例:
知道你什么时间位于哪个范围活动后,通过简单的算法分析,就能推断出你的住址和工作地址——如果你夜里12点到早上8点都停留在一个地方没动,那这儿十有八九是你的家。
如果再综合比对你的邻居们和同事们的位置数据,知道和你有交集的人平时都在哪些消费水平的地段活动,就能轻松为你的消费能力划分等级。
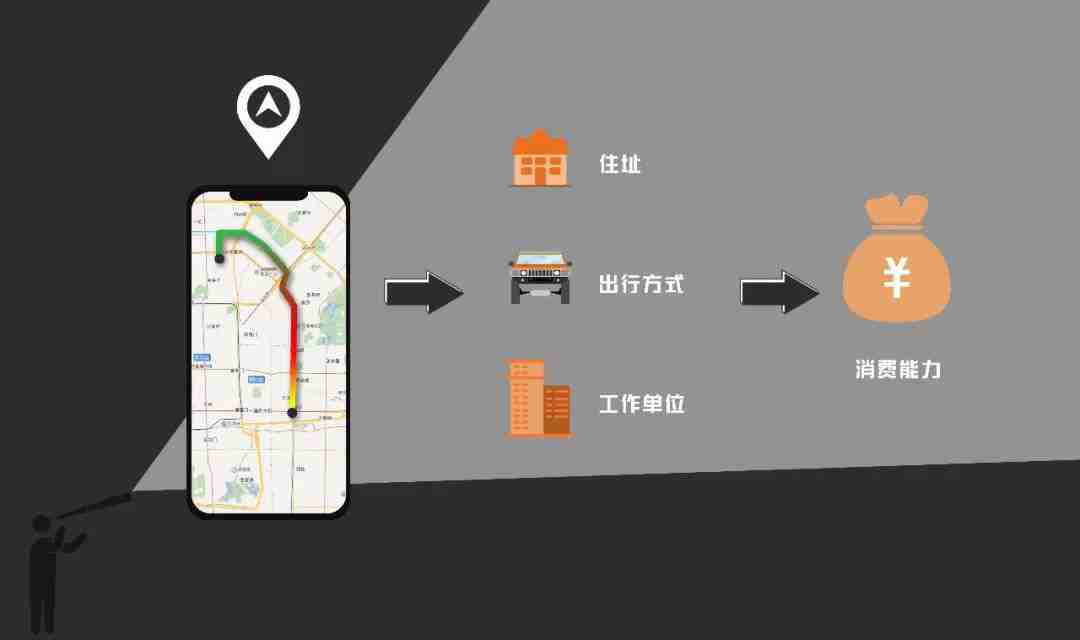
从要求开放位置权限到获得用户的消费能力信息
同样的道理,开放读取短信授权,意味着APP可以读取你所有的信息往来,其中可能包括银行发给你的交易明细记录、你常消费的商家发给你的节假日问候、你出行预定机票酒店的确认信息。
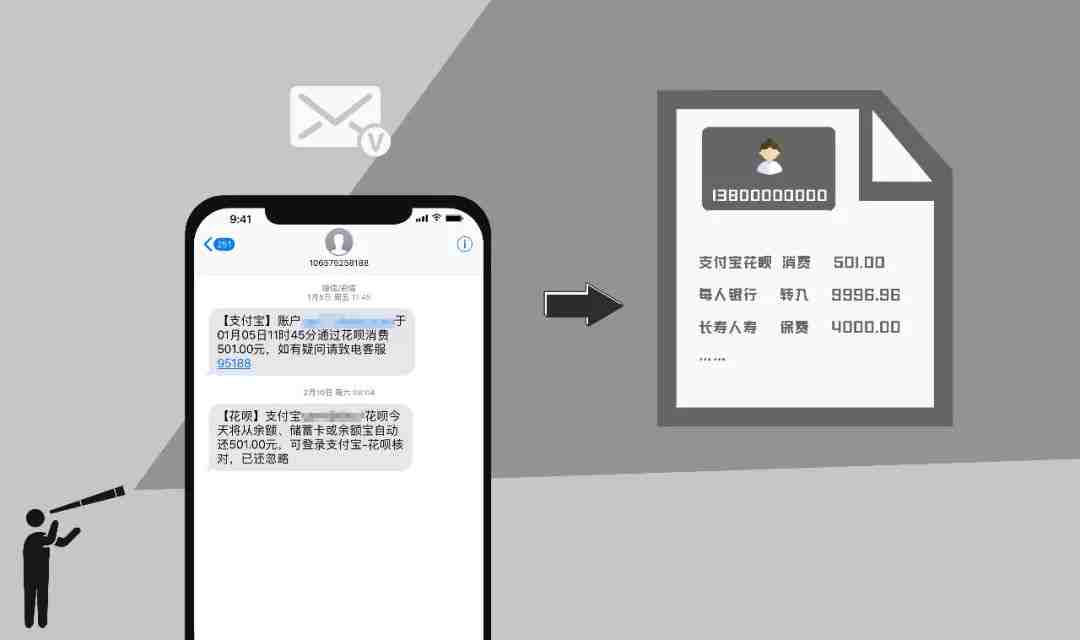
从开放短信授权到获取用户全方位信息
还有更让人意想不到的是Uber经济研究主管Keith Chen在美国国家公共电台(NPR)做节目时曾经讲过一个案例:读取手机电量对APP来说也是一项很有用的数据。在手机电量即将耗尽时,用户愿意承受高达9.9倍的动态溢价。但他也强调,Uber不会这么做。这背后的心理原理很简单:手机没电的人等不了,如果是着急要去一个地方,花多少钱都在所不惜。
随着科技发展给人们提供越来越多的便利,“隐私”的概念也不仅仅是身份证号、电话号码这样的固定信息。那些你以为不太重要的数据,都在不经意间泄露着你的习惯。
2014年,美国一家医疗公司会利用大数据推断病人的发病几率。比如一个哮喘病人,医院可以通过监测他是否购买过香烟、是否居住在高浓度花粉地区来判断急救率。再比如可以综合一个人在健身房锻炼和购买食品的记录,推断他突发心脏病的概率。而这些数据都是医院从相关的网站或者应用购买来的。
最近,亚马逊申请了两项关于手环的专利,能够根据手环的运动轨迹,追踪仓库工人的手部动作。如果发现工人的双手出现在非工作区域,或者不是工作应有的活动频率,可以用震动给他们发出警告……
在庞大的数据面前,人类越来越像一个提供输入的变量角色,任何试图伪装和保护自己的举动,在360度无死角的数据监控下都显得徒劳。
美国技术博客Gizmodo去年曾经采访过一个叫Leila的性工作者。为了保护自己的人身安全,她注册Facebook时使用了和客户联系时完全不同的邮箱、电话,也从不在社交网络上发布和现实身份相关的内容。但有一天,她在Facebook“可能认识的好友”推荐栏里发现了自己现实中的客户。
事实上,Leila自以为精妙的伪装在技术面前非常不堪一击——Facebook会识别用户的设备ID和上网IP来判断你的身份。尽管注册了不同的账号,但只要用同一部手机上网,就有可能被它判断为属于同一个人。
而当大数据对用户拥有充分的了解,多花钱只是大数据应用中对受众伤害最小的“坑”。
扎克伯格最近遇到的信任危机就应证了这一点。他亲自承认Facebook未能及时防范“假新闻”和“仇恨言论”散播、“用户隐私数据”遭窃用、外国势力利用平台“干预”2016年总统选举,并为此道歉。
在一篇叫《人民不再相信科技公司了》的评论文章中,科技媒体品玩的创始人骆轶航把社交网络用户这种在不知不觉的情况下被利用的感觉形容为:“被数据奴役了思维的耻辱感和不安感”。
灰色的不同意
如果你的朋友下载注册了探探,并给它授权了读取通讯录权限,你大概率会收到一条类似这样的推广短信:“你的一位手机联系人在探探上将你设置为暗恋对象……”等你兴冲冲下载注册了,才发现一切都是套路。
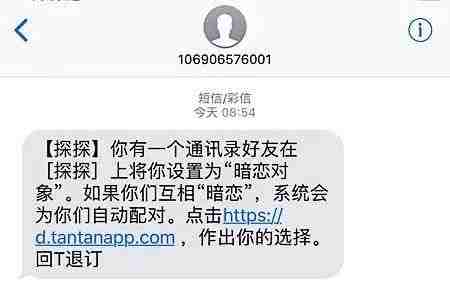
职场社交APP脉脉曾经被昔日的合作伙伴微博起诉,理由是“非法抓取使用新浪微博用户信息”。如果用户通过新浪微博的账号登录脉脉,那么脉脉会把你通讯录里的联系人和微博好友做信息比对,识别他们的身份,即便你的朋友并没有注册和使用脉脉,他们也会被实名列举在你的“一度人脉”列表中。
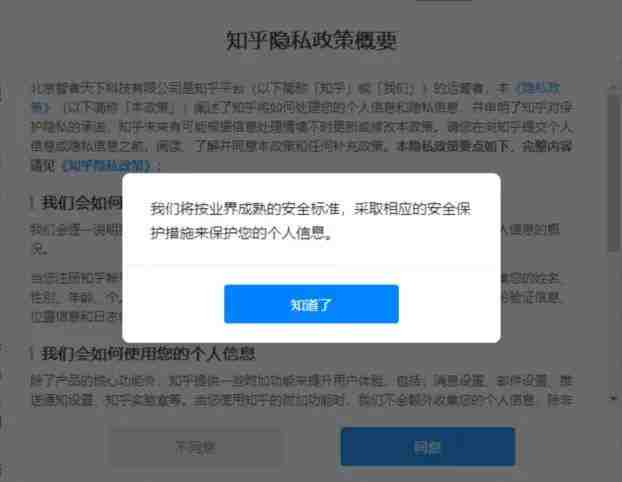
最近,知乎用户打开APP,都会收到一份《用户隐私协议》弹窗,最后一条写道:“您使用或者继续使用我们的服务,即意味着同意我们按照本《隐私政策》收集、使用、存储、共享、转让和公开披露您的相关信息。”
这份协议下方虽然设置了同意和不同意两个按钮,但不同意的按钮是灰色的。如果用户点击同意,则会弹出一个说明,告知“我们将按照业界成熟的安全标准,采取相应的安全保护措施来保护您的个人信息。”至于业界标准是什么,没有再做进一步解释。用户只能选同意,否则就不能再使用知乎APP。
前不久,百度总裁李彦宏在中国发展高层论坛上说,“我想中国人可以更加开放,对隐私问题没有那么敏感,如果他们愿意用隐私交换便捷性,很多情况下他们是愿意的,那我们就可以用数据做一些事情。”
虽然这话不那么顺耳,但我们都清楚,这是实话。
如何监管
在理查德·塞勒这一派的行为经济学家看来,高倍溢价、不同客户端区别定价等“大数据杀熟”做法,无异于向顾客“敲竹杠”,对所有想提升顾客忠诚度的公司来说都不是明智的选择。更重要的是,现实中我们不能仅指望靠行为经济学家的教导和警告就能消除企业的利己选择,而是需要监管者有所作为。在纽约州的一次暴风雨天气中,优步的高倍溢价引起了州总检察长的关注。最后,优步与纽约州签署了三年协议,在“市场遭受非正常混乱”时,优步会使用公式限制其加价的倍数,以遵守纽约州在上世纪70年代油价飙升时通过的防止价格欺诈法律。后来,这起事件成了科技公司与监管机构合作的范例。

脸书公司首席执行官马克·扎克伯格因泄露用户数据参加国会听证会
“大数据”能够实现精准营销,通过给用户精确画像实现靶向传播,满足不同消费者个性化需求。这本是好事,若能依靠技术实现需求的私人定制式满足,当然能增进百姓消费时的获得感。但无论何时,大数据开发商都要筑牢安全保护的防火墙,加宽隐私保障的护城河,以法律为底线,以道德为金线,依法依规进行。否则数据开发越充分,对社会和大众危害越大。如何在商家的大数据精准营销与网络消费者的个体权益保护之间找到一个均衡点,是当下需要研究的课题。
完
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。