解读丨大公司对大数据工程师有哪些要求?


大数据工程师要做哪些工作?
大数据工程师 = 系统工程 + 大规模数据处理 + 数据分析 + 机器学习 + 商业智能
大数据工程师首先是一个系统工程师,也是一个软件工程师。同时,他还得有一些特定的技能,会做大规模数据处理,比如当你的数据有PB量级甚至ZD量级时,你需要会Leverage云平台等,通过几千台机器并行处理,解决大规模数据处理的问题。
大数据工程师还和数据科学家有重叠,二者都要有很强的数据分析能力,比如会用Matlab,R,Python等。仅仅做简单的数据分析可能也不够,大数据工程师还得做机器学习模型,最终我们希望大数据工程师做到的是商业智能。
大数据工程师的最终的目的,是帮助公司提供更好的用户体验,做出最优决策,获取更多的利润。他的工作成果是帮助企业挖掘出数据里的价值,从而实现Data-driven decision making。在个性化、在线广告领域,大数据工程有巨大的商业价值,Yahoo,Facebook,Google的80%以上的收入都来源于广告。通常,大数据工程师要解决的问题是,当一个用户在网站上出现时,如何显示一个与该用户喜好最相关的广告,使他最有可能去点击,从而提高公司的广告收入,这些都是需要通过大数据分析和机器学习建模,帮助做决策。
大数据项目在大公司如何应用?
首先,清楚自己有什么样的数据。
举个例子,地图数据基本被Google Maps和Apple Maps主导,如果你想做一些和用户实时位置相关的大数据应用就会比较困难,除非和别的公司合作或买第三方数据。所以首先要了解你有什么样的数据,你有没有一些独有的数据,如果别的公司没有但你有这些数据,你就可以做一些大数据应用。
又比如,Google有很好的搜索数据,所以它的广告基本是围绕搜索做的,而不会做Yahoo那样的页面显示广告,或者Facebook的Streaming Ads,因为它不是门户或发布者平台,而是一个工具性质的平台。要了解自己的数据的性质是怎样的。
清楚自己要解决什么样的决策问题。
国内的一些阅读应用,比如今日头条,一点资讯,更多地是用大数据做个性化,优化用户体验。而对于Google,Facebook,Yahoo或其他互联网公司,可能要解决的问题是怎样投放更相关的广告,提高点击率和转化率,从而获取更多收入。
根据要解决的问题,整体设计一套大数据系统
设计一套大数据系统的步骤通常包括:
- 数据采集(Logging)
- 数据公路(Data highway):收集完数据后,把数据发到类似于Message queues之类的系统,可以和其他系统进行对接。
- 数据处理 (Processing):如Batch processing,Streaming processing。这一步有很多开源的框架,比如Hadoop, Mapreduce, Spark, Storm,它们应用于不同的领域。Storm是做Streaming processing的,Spark和Mapreduce是做Batch,Spark也可做Streaming。
- 数据存储 (Storage):数据处理完之后得把数据落地,存储下来,用到的工具可能有Hadoop分布式文件系统(HDFS),HBase等。
- 机器学习 (ML, DL):构建机器学习模型挖掘Insights。比如我们可以通过用户的互联网行为数据推断用户画像,比如通过追踪大量他浏览过什么页面,搜索过什么关键词,点击过什么链接,买了什么商品等数据,推断性别、年龄、喜好等,逐渐形成清晰的用户画像。
- 数据取回 (Retrieval):当构建完机器学习模型或用户画像后,会把它存到一个系统里,同时得有一个API帮助把用户画像取出来。
- 数据查询 (Querying)和数据可视化 (Visualization):如果一个广告主想Target一些人群,但不知道他到底能Reach多少人,这时他可输入特定年龄,特定地区,而系统会将满足条件的人数输出,这是数据查询和数据可视化的过程。
大公司对大数据工程师的技能要求
需要掌握哪些语言?
如果你是New grad,面试官期望你熟练掌握一门面向对象的通用语言 (如Java)。如果你只会C++,进公司后可能还是得去熟悉Java,因为很多时候编程语言的选择是与所用框架相关的, 比如Hadoop就是用Java编写的,用C++写Hadoop的应用就不是很方便。
第二,熟悉一门脚本语言 ,如Python,Go. R和Matlab不认为是一个Decent的脚本语言。
对候选人更重要的要求是基本的程序设计素养。如果程序设计功底足够好,熟悉一个新语言就是一两周的事情,面试官可能会从他平时工作的项目里提炼一些问题,看你能不能找到合适的解决方案。
需要掌握哪些技术栈?
对大数据工程师来说,技术栈分几个方向
- 计算框架 (Mapreduce, Spark, Storm, Flink etc);
- 数据存储 (HDFS/Hive, HBase, Cassandra, Redis, MySQL etc);
- 查询系统 (Hive, Presto, Impala, Druid);
- 数据可视化 (Caravel/Superset, ELK);
- 机器学习 (TensorFlow, Caffe, Scikit-learn)
对New Grad来说,大部分的Hiring Manager可能不会看所谓的技术栈。虽然这些候选人的简历里有一些看起来比较Fancy的经验,但大部分人都经不住面试官更加深入的提问,他们认为很多New Grad在以上工具和技术栈上,并没有Hands-on的经验。
如果你有一些大的互联网公司的相关实习经验,可能确实对这些技术栈有好的了解,但如果你只是在学校或者课程设计中用到这些技术栈,用处并不大,因为学校的项目里数据规模不够大,几乎遇不到在实际工作中可能遇到的挑战。比如Hadoop中关于数据偏斜的问题,当数据足够小时,你的代码根本不会遇到这个问题,而在实际工作中是可能出现的。
Hiring Manager主要看重两点,你足不足够聪明,学习能力强不强;你有没有基本的编程素养,会不会算法和设计模式。
对于有经验的工程师,Hiring Manager就比较看重技术栈和相关领域的背景和经验,他期望你一进公司就能干活,甚至领导一个团队。
当候选人的编程能力差不多时,能使他脱颖而出的就是项目经验,特别是主流互联网公司的实习经验。跟申请职位相关的项目经验会加分不少,这样面试时跟面试官的互动会比较顺畅,有共同语言。软技能方面,沟通能力是最重要的软技能要求。
想要成为前景大好、收入又高的大数据工程师,路上有太多需要注意跟提高的方面。BitTiger推出大数据工程师直通车第五期,帮你快速提升所需能力,知识-项目-简历-面试-求职每个环节都有助力,更有系统性的学习业界火热的技术!
课程目标
三个月内完成三个大数据工业级项目,成为Apache火热开源项目的Contributor,全面提升你的背景!
课程安排
第一个月:Apache开源项目强化训练
强化目标:对Apache系列软件的应用及开发能力
- 熟练掌握基于Hadoop的数据分析,Hadoop的基本Use Case和Pig/Hive的编程,有真实大数据系统的实战经验,同时训练具备开源软件的开发能力。
课程内容
- 介绍Hadoop生态系统的主要项目
- 理解并应用DFS、MapReduce、Tez, Zookeeper、Pig、Hive、Oozie, Sqoop、Flume、HBase、Phoenix、Ambari、Nutch、Zeppelin等工具
- 深层理解及应用Hadoop
- Pig及Pig ETL实例
- Hive及用Hive进行数据分析
第二个月:Big Data Infrastructure强化训练
强化目标:搭建一个实时的数据分析平台
- 将从最基础的大数据框架出发,分析它们的优势劣势,学习当前业界最火的系统架构,并将其应用到项目当中,从而构建出一个高性能的实时数据分析平台。
课程内容
- 使用AWS,搭建起属于自己的云服务
- 使用Docker技术,简单快速搭建大数据平台
- 搭建完整的高性能数据pipeline, 从数据采集到利用NoSql数据库数据存储(Cassandra), 到数据传输(Kafka), 再到数据分析(Spark)和最终的数据展示(Nodejs)
- 使用(Zookeeper)以保证平台的高可用性和(Redis)以达到工作压力的合理分配
第三个月:Capstone项目
强化目标
- 在经历两个月高强度学习与实战之后,每位学员将被分配相应的项目目标并在老师的指导下完成。两位主讲老师将以Mentor和Manager的身份监督引导学员完成各自项目。并可以将完成项目作为实习经历写进自己的简历。
Capstone 项目方向会在课程主页上实时更新,欢迎大家及时查看课程主页。
项目实例
- Cloudacl 公司数据挖掘与分析系统
- 开放数据挖掘与分析系统
- Apache Pig和Apache Hive开源项目Contribution
- Alluxio 开源项目Contribution
课程亮点
成为Apache开源项目Contributor
作为华人仅有的4位PMC Chair之一且是多个Apache开源项目的Committer的Daniel老师带领下,你将更加深入、细致地了解诸多Apache开源项目的原理、开发及其应用。同学们更可以通过在Apache开源项目强化训练中提供的项目中提交自己的代码,成为Apache开源项目的Contributor。
增添Bigdata职位实习经历
在完成第三个月的公司实战级别的Capstone项目并得到老师的认可之后的同学,将可以把这段经历作为一个在美短期实习经历写进简历。但因实习名额有限,课程将限制人数。
打造最强简历
完成第一个月的学习及项目之后,你可以将Design a Big Data Stock Platform写进简历中。完成第二个月的学习及项目之后,你将在拥有新的项目之后同时成为知名开源项目的Contributor。完成第三个月的Capstone项目之后,你将拥有资格将本次经历写成为实习经历,放进简历中。
Mock Interview
学员在直通车期间可预约一次1h的mock interview。学员预约前需提交更新后的简历。Mock interview之后1周内,学员将收到反馈和具体的意见。学员须提交文字版mock interview reflection, 分析自己在过程中的不足之处,并提出改进方案。
强大面试指导
直通车课程名师组将从BigDataEnginner面试常见考点,面试必备知识技能,面试流程,职业发展等多方面为学员们做详细的面试指导。直通车课程组将发挥BitTiger广大社交网及BitTiger内部资源竭尽全力帮助本项目优秀学员内推,从而赢得心仪offer。
顶尖教师团队
Daniel Dai
Principal Software Engineer @ Hortonworks
Hortonworks初创团队的23个员工之一,目前担任Apache Pig的PMC Chair, Apache Hive的Committer,多个Apache项目的Champion和Mentor,是O’Reilly 《Programming Pig》一书的作者。
Uncle Barney
Sr. Software Engineer @ Unity Technologies
Uncle Barney 热爱研究学习各种分布式系统,现于Autodesk Cloud Infrastructure组担任高级软件工程师,从事分布式系统和云计算相关工作,曾就职于MathWorks,开发了Matlab的HDFS/Cassandra/MongoDB connector。
JZ
分布式存储系统方向博士,毕业前主要研究如何提高大数据(分布式)存储系统的可靠性,可扩展性和节能。现在主要负责针对对各种大数据平台系统的评测,开发,部署以及大数据应用的开发。
往期学员评价
Daniel老师超级赞!我原先以为我在这里学到的东西可能会对我职业生涯前几年产生重要影响,但现在发现,可能对我整个职业生涯都有重要影响。老师的debug方法真的先进又实用,很多工业届人士还仍然只会肉眼debug。
——学员王同学
巴叔讲的理论实战课非常有用,尤其是把数据流的整体架构讲的很清楚。 实践部分的内容非常好,能够帮助更有效的理解理论课的知识点,而且完成实践作业的过程也是一个很好的学习机会,尝试解决遇到的各种问题同样能够提高自己的能力。
——学员Jack
巴叔真男神,讲课深入浅出,细致到位,答疑也耐心细致,及时帮我解决问题,谢谢巴叔!
——学员吴同学
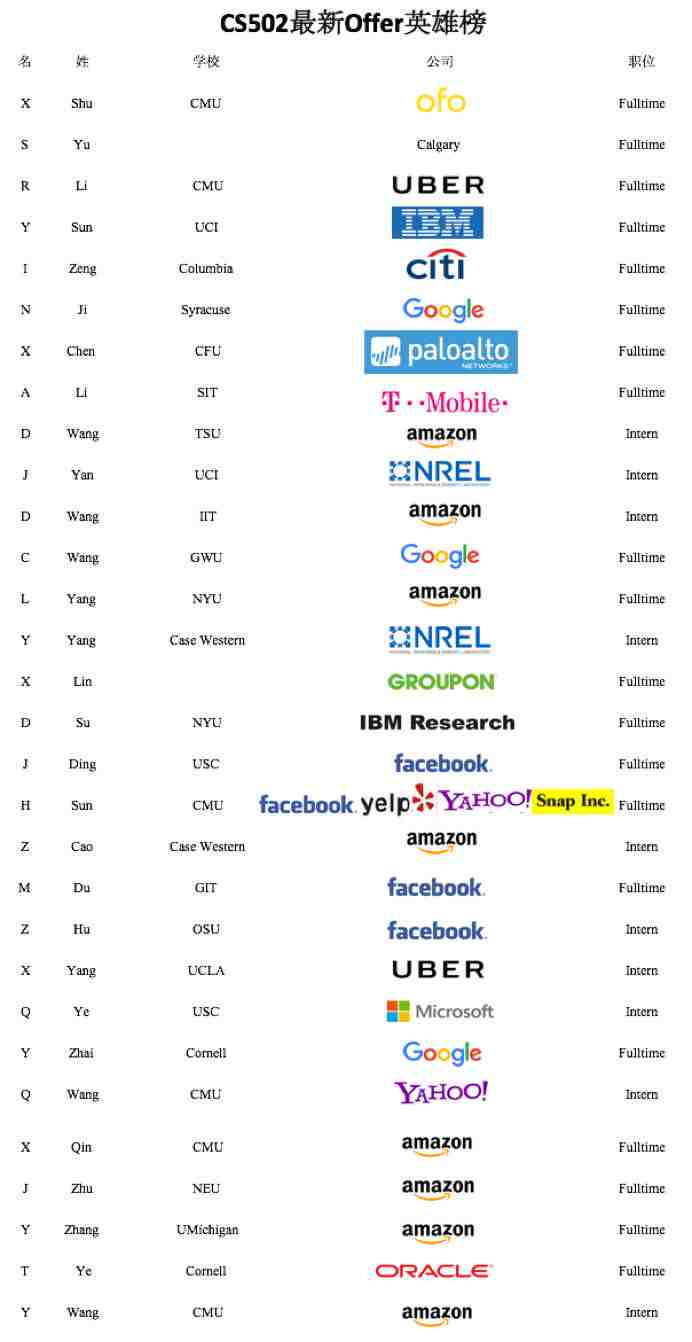
最新Offer英雄榜
报名第一节课程(免费)
复制链接或点击“阅读原文”
https://www.bittiger.io/livecourses/3wcjeAbeNQTBg5nKZ
点击“报名第一节课(Free Lecture)”,填写资料即可报名
课程咨询及报名申请流程
将简历发送至[email protected], 邮件主题请设置为“大数据工程师直通车”
内容包括
- 你的简历
- 你的微信ID
- 为什么想参加此门课程
课程组老师会在收到简历后24小时内进行简历背景评估,并电话回访及Career指导
查看详细课程大纲,公众号后台回复“CS502”
或添加课程负责人Davy直接咨询


最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。