直播|如何用Python实战Uber用户数据分析?


从Programming(Python),Machine Learning和Business Insight三个角度全方位带你实战Uber用户数据分析。

课程内容
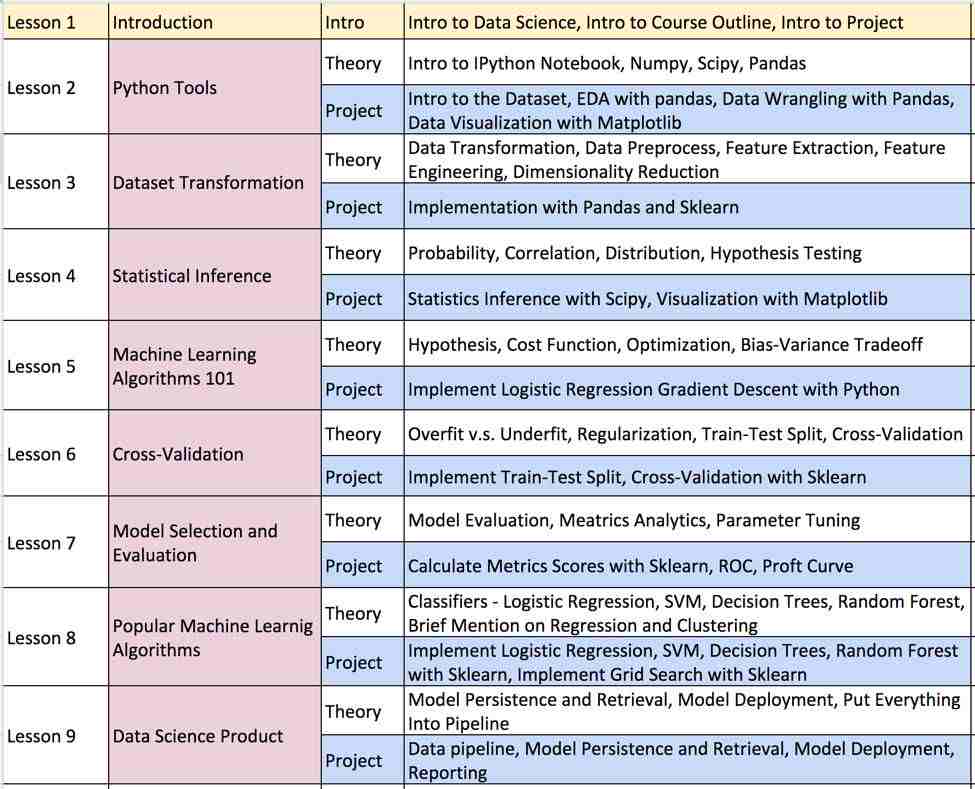
语言和工具箱:Python, iPython Notebook, Pandas, Numpy, Scipy, Sklearn, Matplotlib等 机器学习模型:Logistic Regression, SVM, Decision Tree, Random Forest等
介绍自己如何一步步走上DS 我行你也行 B. Splunk Machine Learning Toolkit Data Science行业介绍 起源 定义 市场需求 Data Science 核心知识 问题分类 解决方法 Deep Learning v.s. Shallow Learning 模型好坏的判断与选择 如何正确使用模型 应用领域 课程大纲介绍 技术栈 流程 项目简介 展示项目结果



邮件咨询


最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。