Apache Spark 2.0最新进展:更快,更容易,更智能

5月5日,Reynold Xin,Spark的核心成员、Databricks的联合创始人,在网上针对Spark 2.0进展讲座。笔者之前也参加过一些大数据大会,Spark在业界的逐渐普及已是不争的事实。它是一个开源的大数据处理引擎,能够被用于解决各界面临的高难度数据问题。这次升级是一个很了不起的Milestone,非常期待正式版发布。在6月6-8日,在SF召开Spark Summit大会。
https://spark-summit.org/2016/
看了一下keynote发言人,一大堆大牛:比如Matei Zaharia, Doug Cutting, Jeff Dean, and Andrew Ng ,工业界也鼎力支持,从大公司IBM,微软,华为,到一些创业新贵Airbnb,Uber等。
总体上Spark 2.0提升了下面3点:
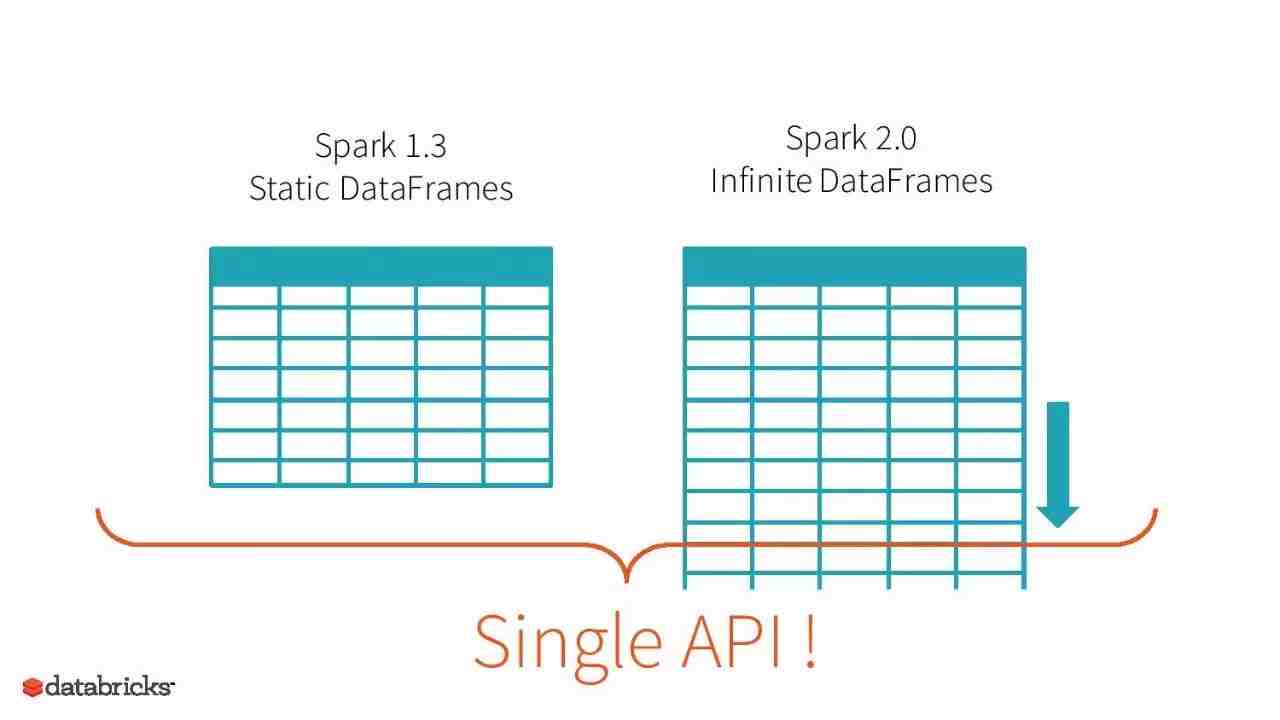
1. 对标准的SQL支持,统一DataFrame和Dataset API。现在已经可以运行TPC-DS所有的99个查询,这99个查询需要SQL 2003的许多特性。
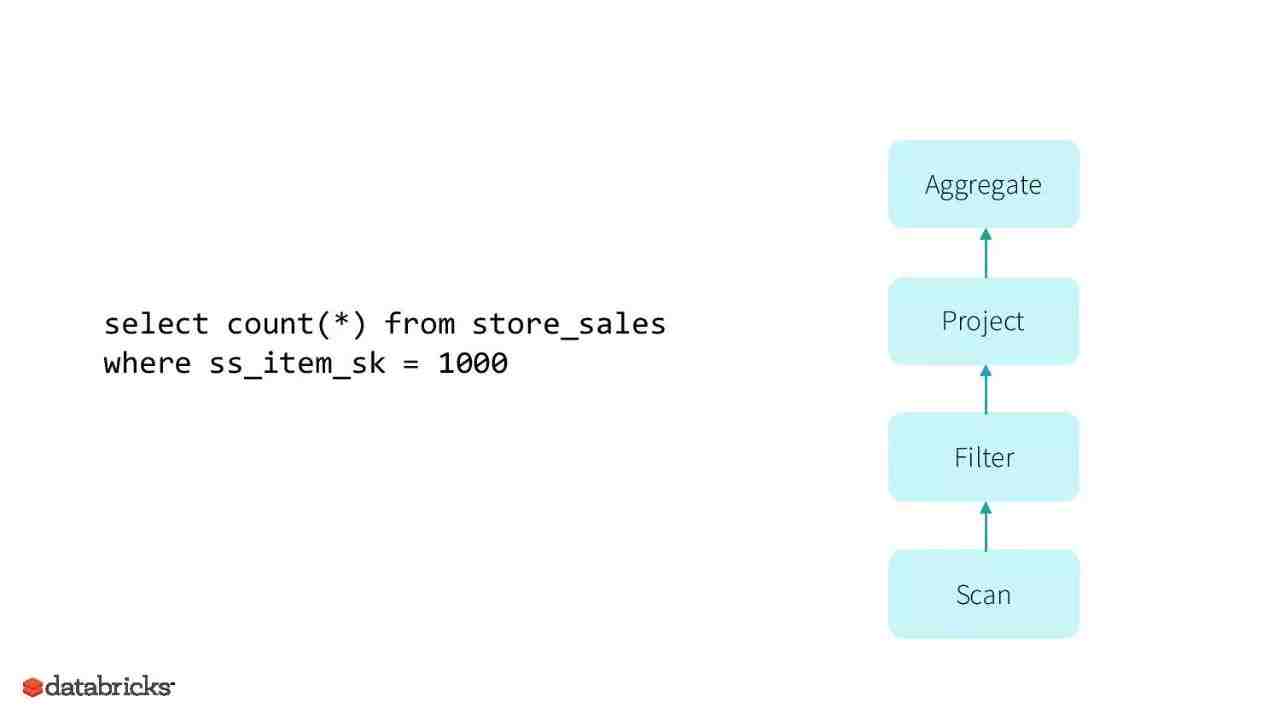
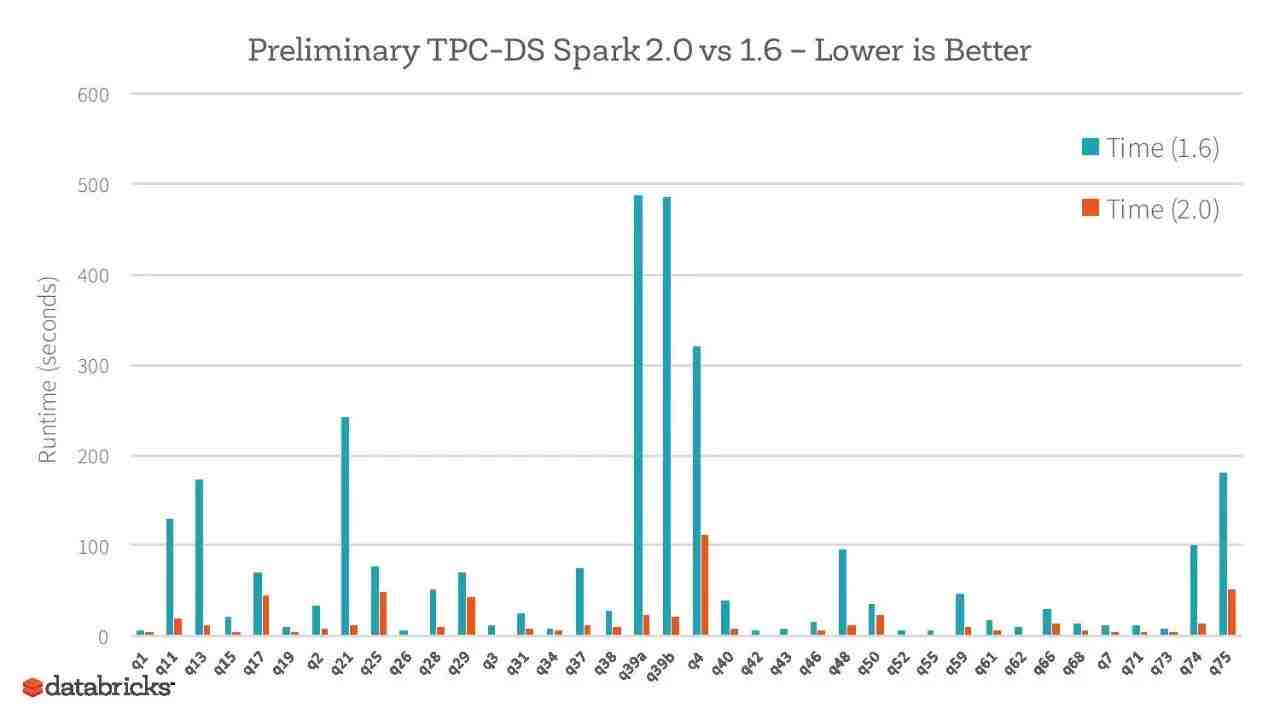
2. 采用第二代Tungsten engine,建立在现代编译器和MPP数据库的想法上,并且把它们应用于数据的处理过程中。主要想法是通过在运行期间优化那些拖慢整个查询的代码到一个单独的函数中,消除虚拟函数的调用以及利用CPU寄存器来存放那些中间数据。最高性能提升10倍。
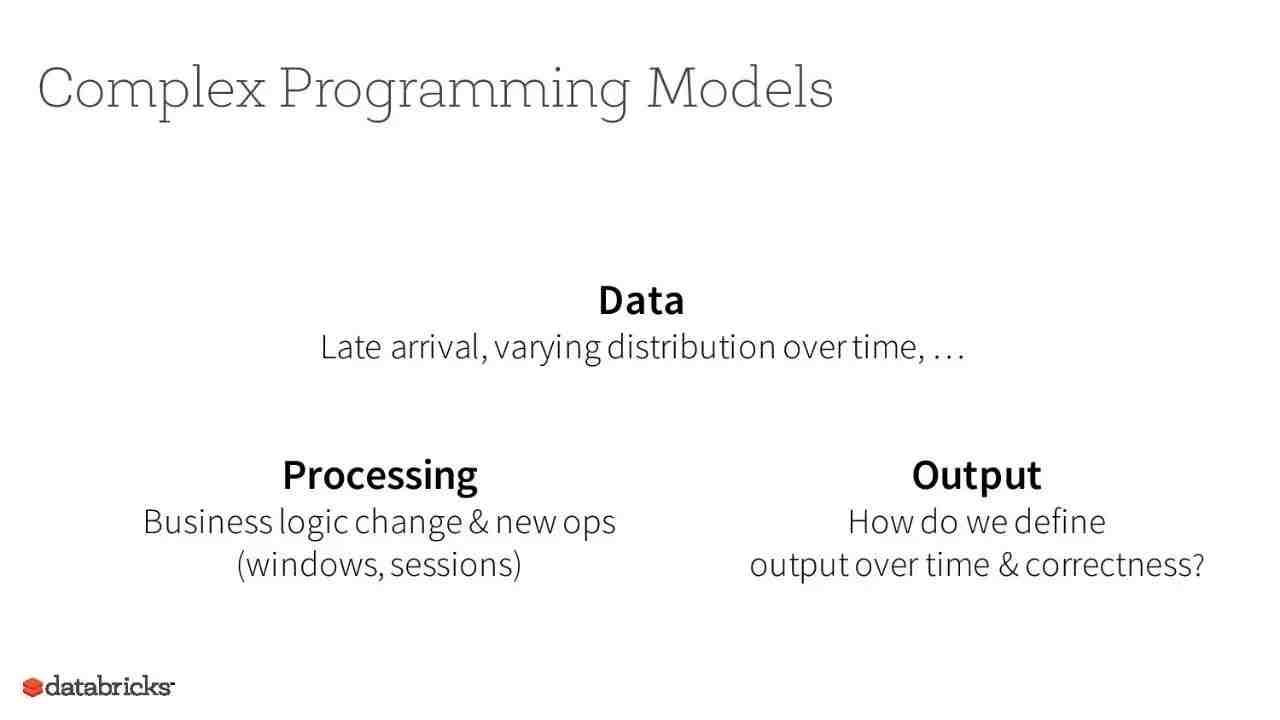
3. 一种新颖的流处理方式:Structured Streaming APIs,利用Catalyst优化器来发现什么时候可以透明的将静态的程序转到增量执行的动态工作或者无限数据流中。当我们从这个数据结构的角度来看到我们的数据,这就简化了流数据。
下面是讲义干货

































参考:https://databricks.com/blog/2016/05/11/apache-spark-2-0-technical-preview-easier-faster-and-smarter.html
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。