职悠学堂|带你零基础搞定Hadoop


大数据,想必大家经常听到这个被炒得很热的话题。随之而来的是各种看似高大上的专业术语,比如扩展性、可靠性、容错性,好像真的很高深,要积累多年经验才能学习。
但另一方面,很多同学都刚刚进入互联网这个行业,对分布式计算还没有很多了解,那是不是就要花很多力气才能搞懂大数据呢?不必担心,包子老师在这里用浅显易懂深入浅出的语言,帮助没有基础的同学快速的入手大数据,让每位同学都能迅速学会最前沿的技术。今天,我们先学习当前使用最广泛的大数据处理框架 Hadoop。
Hadoop,你是怎么来的?
今天的社会产生越来越多的数据,比如:你登录Facebook以后点击了哪些好友,你在Amazon上浏览了哪些产品,你在linkedin上浏览了哪些公司,甚至到从石油矿井里的钻头收集了哪些地质信息。
我们还发现,通过分析这些数据总结规律,我们可以让Facebook和Amazon显示让用户更感兴趣的广告,公司HR会更准确找到合适的求职者,石油公司也能用更低的成本开采更多的石油。
那找个软工写算法不就行了吗?
确实,这些决策都是通过算法找到规律的。可问题是现在的数据量太大了,一台机器要完成一个问题要算好久好久。
那用多台机器处理不就行了吗?
确实,Hadoop以及其他任何大数据框架都是多台机器共同处理的。可问题是,这些算法都要完成一个特定的问题,给出一个答案,多台机器不能自己算自己的,他们要有不同的分工,联合起来共同算完这个问题。这里就是Hadoop等框架的特长。
我们举个例子吧:
Google是大家常用的搜索引擎,作为业务的重要特征,它自然想知道大家对哪些关键字感兴趣,比如以天为单位,收集所有人搜过的关键字,统计其出现的次数。
这听起来像个哈希表就能干的问题对吧?可是,每天那么多人使用Google,它不可能把这些关键字都放在内存里,而且Google也是用很多服务器为大家完成搜索的,所以一天里所有搜过的关键字,都以文件的形式存在多台机器上。我们就叫这些机器1, 2, 3......n.
比如在机器1上存储了一个文件,内容是所有搜过的关键字:Deer, Bear, River …...
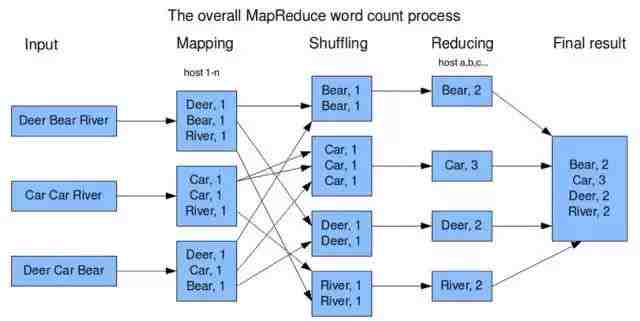
图1
既然Log文件存放在多台机器中,那如何计算关键字出现的总次数呢?
一种直观的算法,就是先让每台机器统计本机上每个关键字的搜索次数,写段算法统计一个文件里的关键字很简单。比如机器1的处理结果为:
Deer 150000
River 110000
Car 100000
…
(参见图1的mapping)
注意到这里,每台机器知道的是本机上关键字的搜索次数,而我们关心的是所有机器上的关键字的搜索总次数。
那下一步再找一组机器,不妨称其为:A, B, C, D......
每台机器只统计一部分关键字出现在所有机器上的总次数,比如:
让机器A统计 在机器1, 2, 3.......n上“Bear”出现的总次数;
让机器B统计,在机器1, 2, 3.......n上“Car”出现的总次数;
让机器C统计,在机器1, 2, 3.......n上“Deer”出现的总次数;
让机器D统计,在机器1, 2, 3......n上“River”出现的总次数;
(参见图1的reducing)
这样,当A, B, C, D......完成自己的任务以后,我们就知道每个关键字在过去一天出现的次数了。
所以每台机器不但要计算自己的任务,还要和其他机器「合作」,在我们刚才的例子里就是机器A, B, C, D......要从机器1, 2, 3, 4......那里知道关键字的出现次数,而且,A, B, C, D.....还要沟通好,分别统计不同的关键字,即不能两台机器都统计同一个关键字,也不能有的关键字没有机器统计。
那Hadoop总结了算法的哪些共同点呢?
那篇MapReduce Paper的作者发现,很多计算,就比如我们刚才的例子,都可以拆分成Map, Shuffle, Reduce三个阶段:
Map阶段中,每台机器先处理本机上的数据,像图1中各个机器计算本机的文件中关键字的个数。
各个机器处理完自己的数据后,我们再把他们的结果汇总,这就是Shuffle阶段,像刚才的例子,机器A, B, C, D......从1-n所有机器上取出Map的结果,并按关键字组合。
最后,进行最后一步处理,这就是Reduce,我们刚才的例子中就是对每一个搜索关键字统计出现总次数。
这几步我们就称为MapReduce Model.
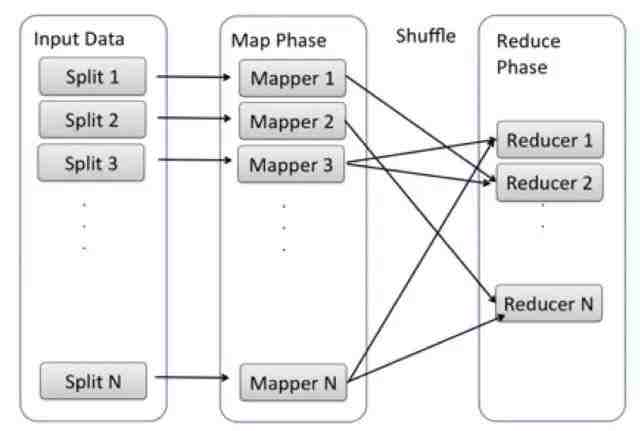
图2
为了完成MapReduce Model的计算,实际开发的软件需要一些辅助的功能。想像一下,起始时的一组机器上面存储了要处理的数据,但是Map, Shuffle, Reduce阶段的Function在哪儿呢?所以我们需要把Mapper Function, Reducer Function (Java code或者其他语言的code) 安装在机器 1-n 和A-Z上,并且执行。而且在Map阶段以后,计算结果保存在本机上,没办法Shuffle到Reduce的机器上。所以,也需要有软件按照Shuffle算法,把Mapper Function的结果搬运到Reduce阶段的机器上。
运行整个Hadoop Job的流程中,很多工作对于所有算法都是需要的,不同的算法只是Mapper Function和Reducer Function. 换句话说,Hadoop实现了通用的功能,开发人员只需要告诉Hadoop需要执行的Mapper, Reducer Function,就可以完成想要的计算,而不需要开发所有步骤。
在微信平台中回复“帮助”可查看更多文章。
在微信平台中回复“服务”可了解职悠课程。
本文转载自:Careeyo.com,包子铺里聊IT
Careeyo独家整理修改,版权归原作者所有,若需引用请注明出处。



最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。